"Alors que la popularité d’autres langages de programmation a pu fluctuer de manière significative, Python a résisté à l’épreuve du temps et s’est imposé comme un langage de choix pour de nombreux développeurs de tous niveaux, du débutant à l’expert." (Permalink)
C’est sous la licence MIT, l’une des licences open source les plus permissives, que DeepSeek, acteur chinois de la GenAI, a publié ce jeudi 26 décembre la dernière version de son modèle éponyme. L’annonce de DeepSeek-V3 a d’autant plus suscité l’attention que les performances du modèle seraient comparables, voire supérieures à celles de principaux modèles à source fermée, comme GPT-4o ou Claude 3.5 Sonnet, et ce, malgré un coût d’entraînement drastiquement réduit.
Alors que la guerre technologique autour de l’IA entre les Etats-Unis et la Chine continue de s’intensifier avec l’annonce il y a moins d’un mois de nouvelles restrictions, DeepSeek démontre qu’il est néanmoins possible de développer des LLMs capables de rivaliser avec les meilleurs modèles américains.
Créée en mai 2023 à Hangzhou, la start-up, dirigée par Liang Wenfeng, est une filiale du fonds spéculatif High-Flyer. Son ambition est la même que celle affichée par OpenAI : développer une IA au service de l’humanité et atteindre l’IAG, des systèmes d’IA qui dépassent les capacités cognitives des êtres humains dans de nombreux domaines.
Tout juste un an plus tard, l’entreprise lançait DeepSeek-V2, un modèle de langage performant proposé à un coût compétitif, déclenchant une guerre des prix sur le marché chinois de l’IA et amenant ses principaux concurrents notamment Zhipu AI, ByteDance, Alibaba, Baidu, Tencent à revoir leurs prix à la baisse.
La semaine dernière, elle a présenté son successeur, DeepSeek-V3, comptant 671 milliards de paramètres, entraîné durant un peu moins de deux mois grâce aux GPU H 800 que les USA autorisaient NVIDIA à lui vendre jusqu’à l’an passé. Un total de 2 788 000 heures estimé à un coût de 5 576 000 par million de tokens en entrée, 1,10 $ par million de tokens en sortie.
Le modèle est téléchargeable sur Hugging Face. Le code complet ainsi qu’une documentation technique détaillée sont quant à eux disponibles sur GitHub.
DeepSeek-V3 : quand l'open source chinois défie les LLMs américains de pointe
Pleias, une start-up française, annonce le lancement de sa première famille de grands modèles de langage (LLM), définissant de nouvelles références en matière de transparence, d’éthique et de conformité. Ces modèles compacts, qui s’appuient exclusivement sur des données ouvertes, démontrent que performance technologique, respect du droit d’auteur et open source peuvent aller de pair.
Pleias est une start-up parisienne créée en décembre 2023 par Pierre-Carl Langlais, Ivan Yamschikov et Anastasia Stasenko. Ses modèles sont élaborés à partir du Common Corpus, un ensemble de données multilingues unique par son ampleur et son ouverture. Ce corpus, qu’elle a publié le 13 novembre dernier, disponible sur HuggingFace, a été soutenu par la start-up d’état Langu:IA, un projet du ministère de la Culture et la DINUM, dans le cadre de la préfiguration de l’offre de services de l’Alliance pour les technologies du langage EDIC (ALT-EDIC).
Son développement a réuni un consortium exceptionnel de partenaires, dont le cluster de supercalculateurs Jean-Zay (Genci, Idris, Eviden), NVIDIA, TractoAI, Wikimedia Entreprise. Il a également bénéficié du soutien de grandes organisations open-source, dont la Mozilla Foundation, l’AI Alliance et Eleuther AI, renforçant son engagement envers la science ouverte et l’innovation collaborative.
Comptant plus de 2 000 milliards de tokens, le Common Corpus est le plus grand ensemble de données d’entraînement pour les LLMs exclusivement composé de textes appartenant au domaine public.
Il se distingue par plusieurs caractéristiques fondamentales :
Véritablement ouvert : toutes les données incluses sont sous licences permissives, garantissant une utilisation en conformité avec les droits d’auteur ;
Multilingue et diversifié : plus de 30 langues sont représentées, notamment l’anglais (808 milliards de tokens) et le français (266 milliards), ainsi que des langues comme l’espagnol, l’italien et le néerlandais. Les sources incluent des articles académiques, des textes juridiques, du contenu culturel et du code open source ;
Qualité optimisée : les contenus ont été rigoureusement filtrés pour éliminer les données nuisibles ou de faible valeur informative.
Une suite adaptée aux besoins européens
Pleias présente trois modèles qui sont, de par leurs données d’entraînement, entièrement conformes au RGPD et à l’AI Act européen :
Pleias 1.0 : avec 3 milliards de paramètres, il est spécialisé dans les domaines de la gestion des connaissances et des applications administratives ou juridiques ;
Pleias-Nano (1 milliard) et Pleias-Pico (350 millions) : conçus pour des usages plus légers comme la génération augmentée par la récupération (RAG) et l’harmonisation des données.
Ils fonctionnent efficacement sur du matériel grand public, leur petite taille les rendant particulièrement adaptés aux environnements où les ressources informatiques sont limitées ou pour des applications nécessitant une faible latence.
Anastasia Stasenko, PDG de Pleias, conclut :
“Notre approche démontre qu’il est possible de créer des modèles de langage puissants tout en respectant pleinement la loi sur le droit d’auteur, les exigences du RGPD et les principes éthiques de l’IA”.
Pleias : des modèles de langages ouverts pour une IA éthique et transparente
Depuis l’émergence des grands modèles de langage (LLMs), certains ont été qualifiés d’“ouverts”, ce qui a pu prêter à confusion avec le terme “open source” lors de leur présentation. En février dernier, l’Allen Institute for Artificial Intelligence (Ai2), a publié la première version d’OLMo, (Open Language Model), un LLM qui répond aux critères stricts de l’OSAID, la définition de l’IA open source de l’OSI. Le modèle a depuis été mis à jour en avril et dernièrement avec OLMo 2 qu’il présente comme “le meilleur modèle de langage entièrement ouvert à ce jour”.
AI2 est un institut de recherche à but non-lucratif fondé en 2014 par Paul Allen, philanthrope et cofondateur de Microsoft, décédé en 2018. Son objectif est de favoriser le développement de l’intelligence artificielle au service de la société, en mettant l’accent sur des applications responsables et éthiques. L’institut collabore avec des universités, des entreprises et d’autres institutions de recherche pour stimuler l’innovation dans ce domaine.
AI2 se concentre sur des domaines variés tels que la compréhension du langage naturel, la vision par ordinateur, l’apprentissage automatique et la robotique. Parmi ses contributions majeures, on trouve Semantic Scholar, un moteur de recherche avancé destiné à aider les chercheurs à accéder et à analyser des articles scientifiques, ainsi que AllenNLP, une bibliothèque open source dédiée au traitement du langage naturel.
OLMo 2
Dans le domaine de la GenAI, AI2 milite également pour l’open source. Après Molmo, une famille de modèles d’IA multimodaux, il présente OLMo2, sa dernière famille de modèles de langage.
Dans le cadre de la validation et de la mise à l’essai de l’OSAID, la première version d’OLMo a été considérée comme réellement open source tout comme Pythia (Eleuther AI), Amber et CrystalCoder (LLM360) et T5 (Google) contrairement à Llama de Meta ou Grok de xAI. OLMo 2 correspond lui aussi pleinement aux critères exigés.
AI2 écrit sur son blog :
“Parce que la science entièrement ouverte nécessite plus que des poids ouverts, nous sommes ravis de partager une nouvelle série de mises à jour d’OLMo, y compris des poids, des données, du code, des recettes, des points de contrôle intermédiaires et des modèles optimisés pour les instructions, avec la communauté plus large de la modélisation du langage !”
Une architecture améliorée et un pré-entraînement optimisé
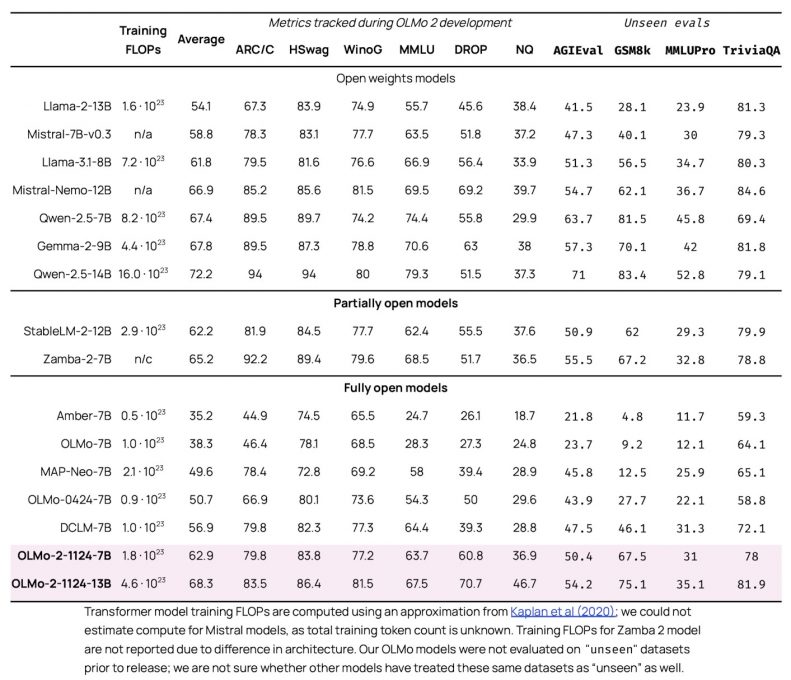
OLMo 2 est une nouvelle famille de modèles de langage de 7 et 13 milliards de paramètres, le premier a été entraîné sur environ 4,05 milliards de tokens tandis que le second l’a été sur un total de 5 000 milliards de tokens.
Les modifications architecturales principales apportées à OLMo incluent l’intégration de RMSNorm pour une meilleure stabilité et l’utilisation de plongements positionnels rotatifs.
AI2 a utilisé une approche en 2 étapes. Pour la 1ère, les modèles ont été pré-entraînés avec OLMo-Mix-1124, une collection d’environ 3,9 milliards de jetons. Les modèles ont, dans un second temps, été affinés avec un mélange composé à part égale de données web filtrées et de données spécifiques à un domaine (contenu académique, forums de questions-réponses, données d’instructions et cahiers d’exercices mathématiques, à la fois synthétiques et générés par l’homme) provenant de Dolmino-Mix-1124. L’Institut a ensuite échantillonné les 843 milliards de tokens obtenus pour optimiser leurs performances lors des étapes finales d’entraînement.
Performance et comparaison de OLMo 2
Selon les évaluations d’AI2, OLMo 2 7B et 13B sont les meilleurs modèles entièrement ouverts à ce jour, surpassant souvent les modèles de “poids ouverts” de taille équivalente, tout en égalant voire dépassant certains modèles partiellement propriétaires. Par exemple, OLMo-2-7B surpasse Llama 3.1 8B de Meta tandis qu’OLMo-2-13B dépasse Qwen 2.5 7B d’Alibaba Cloud malgré un coût de calcul moindre.
AI2 a utilisé Tülu 3, sa famille de modèles de suivi d’instructions, pour les variantes Instruct d’OLMo 2. Celles-ci ont été évaluées sur leurs capacités de suivi d’instructions, de rappel des connaissances, de mathématiques et de raisonnement général. Elles se sont révélées compétitives avec les meilleurs modèles à poids ouverts, OLMo 2 13B Instruct surpassant les modèles Qwen 2.5 14B instruct, Tülu 3 8B et Llama 3.1 8B instruct.
L’IA peut-elle améliorer la précision des diagnostics médicaux ? Des chercheurs d’UVA Health, un réseau de soins de santé affilié à l’Université de Virginie, ont tenté de répondre à cette question. Le résultat de leur étude est surprenant : si l’IA peut effectivement surpasser les performances des médecins dans certaines tâches de diagnostic, son intégration dans leur flux de travail n’a pas significativement amélioré leurs performances globales.
Les grands modèles de langage (LLM) ont montré des résultats prometteurs dans la réussite aux examens de raisonnement médical, qu’il s’agisse de questions à choix multiples ou de questions ouvertes. Cependant, leur impact sur l’amélioration du raisonnement diagnostique des médecins en situation réelle reste à déterminer.
Andrew S. Parsons, qui supervise l’enseignement des compétences cliniques aux étudiants en médecine de la faculté de médecine de l’Université de Virginie et codirige le Clinical Reasoning Research Collaborative, et ses collègues de l’UVA Health ont voulu mettre ChatGPT Plus (GPT-4) à l’épreuve. Leur étude, a été publiée dans la revue scientifique JAMA Network Open et acceptée ce mois-ci par le symposium 2024 de l’American Medical Informatics Association.
Méthodologie de l’étude
Les chercheurs ont recruté 50 médecins exerçant en médecine familiale, en médecine interne et en médecine d’urgence pour lancer un essai clinique randomisé et contrôlé dans trois hôpitaux de pointe : UVA Health, Stanford et le Beth Israel Deaconess Medical Center de Harvard. La moitié d’entre eux ont été assignés aléatoirement à l’utilisation de ChatGPT en plus de méthodes conventionnelles telles que Google ou des sites de référence médicaux comme UpToDate, tandis que l’autre moitié s’est appuyée uniquement sur ces méthodes conventionnelles.
Les participants ont eu 60 minutes pour examiner jusqu’à 6 vignettes cliniques, des outils pédagogiques utilisés dans le domaine médical pour évaluer et améliorer les compétences cliniques des professionnels de santé. Ces vignettes, basées sur des cas réels, comprenaient des détails sur les antécédents des patients, des examens physiques et des résultats d’analyses de laboratoire.
Résultats
L’étude a révélé que les médecins utilisant ChatGPT Plus obtenaient une précision diagnostique médiane de 76,3 %, légèrement supérieure aux 73,7 % des médecins s’appuyant uniquement sur des outils traditionnels. Si l’écart reste modeste, en revanche, Chat GPT Plus, utilisé indépendamment, a atteint une précision impressionnante de 92 %.
Si les participants à l’essai utilisant ChatGPT Plus ont atteint un diagnostic un peu plus rapidement dans l’ensemble (519 secondes contre 565 secondes par cas), paradoxalement, ils ont réduit la précision diagnostique de l’IA.
Pour les chercheurs, cette baisse de la précision pourrait être due aux invites utilisées. Ils soulignent la nécessité de former les cliniciens à l’utilisation optimale de l’IA, notamment en exploitant les prompts de manière plus efficace. Sinon, les organisations de soins de santé pourraient acheter des invites prédéfinies à mettre en œuvre dans le flux de travail et la documentation clinique.
Selon eux, ChatGPT Plus se comporterait probablement moins bien dans la vie réelle, où de nombreux autres aspects du raisonnement clinique entrent en jeu, en particulier pour déterminer les effets en aval des diagnostics et des décisions de traitement. Ils demandent des études supplémentaires pour évaluer les capacités des grands modèles de langage dans ces domaines et mènent une étude similaire sur la prise de décision de gestion.
Conclusions
Les résultats révèlent une nuance essentielle : bien que les LLM soient capables de performances autonomes impressionnantes, leur utilisation en complément des méthodes traditionnelles n’a pas significativement amélioré la précision diagnostique des médecins.
Les chercheurs avertissent que “les résultats de cette étude ne doivent pas être interprétés comme indiquant que les LLM devraient être utilisés pour le diagnostic de manière autonome sans la surveillance d’un médecin” ajoutant que “des développements supplémentaires dans les interactions homme-machine sont nécessaires pour réaliser le potentiel de l’IA dans les systèmes d’aide à la décision clinique”.
Ils ont d’ailleurs lancé un réseau bicôtier d’évaluation de l’IA appelé ARiSE (AI Research and Science Evaluation) afin d’évaluer davantage les résultats de la GenAI dans les soins de santé.
Equipe de recherche : Ethan Goh, Robert Gallo, Jason Hom, Eric Strong, Yingjie Weng, Hannah Kerman, Joséphine A. Cool, Zahir Kanjee, Andrew S. Parsons, Neera Ahuja, Eric Horvitz, Daniel Yang, Arnold Milstein, Andrew P.J. Olson, Adam Rodman et Jonathan H. Chen.
GenAI et diagnostic médical : des résultats potentiellement prometteurs mais une intégration à affiner
En juin dernier, ABBYY, une multinationale spécialisée dans le traitement intelligent des documents et l’automatisation, a mené, en partenariat avec l’institut Opinium, une enquête auprès de 1 200 décideurs informatiques en France, au Royaume-Uni, aux États-Unis, en Allemagne, en Australie et à Singapour. Elle dévoile dans son rapport “ABBYY State of Intelligent Automation : AI Trust Barometer 2024”, les motivations et les inquiétudes des industriels français face à l’adoption de l’IA.
Selon les chiffres d’ABBYY, l’investissement moyen dans l’IA au cours des 12 derniers mois en France a été supérieur à celui des pays étudiés : 811 000 euros alors que la moyenne se situe à 600 000 euros. L’étude révèle que l’innovation technologique et la peur de l’obsolescence sont les principaux moteurs de l’intégration de l’IA.
Le “AI Trust Barometer 2024″ identifie également les principaux domaines d’application de l’IA dans l’industrie française : le marketing et les opérations (40 %), les ventes (39 %), et la conformité (27 %) sont en tête des départements ayant intégré des outils IA, avec des solutions d’automatisation qui transforment progressivement les processus internes et la relation client.
La peur de l’obsolescence : premier facteur de motivation
Alors que la technologie évolue à une vitesse inédite, 63 % des industriels français expriment leur crainte de se voir dépassés s’ils ne s’adaptent pas à l’IA. Ce chiffre souligne la pression constante qui pèse sur les entreprises pour maintenir leur compétitivité. Selon ABBYY, l’IA est devenue un élément clé pour garantir l’efficacité : 52 % des répondants, indiquent l’amélioration des performances et du service client comme des objectifs prioritaires. La pression exercée par les clients s’avère également significative, 38 % des répondants affirmant que les attentes de leurs consommateurs les poussent à investir dans l’IA.
Des décideurs confiants dans les modèles de langage
Une large majorité des leaders informatiques du secteur industriel français (77 %) déclare faire confiance à l’IA pour apporter des avantages à leur entreprise.
Ils accordent une confiance élevée aux grands modèles de langage (LLM), plébiscités par 84 % des répondants pour leur fiabilité et leur efficacité. Les petits modèles de langage (SLM) bénéficient eux aussi d’une confiance notable (80 %), en partie en raison de leur capacité à répondre à des besoins spécifiques tout en limitant certains risques associés aux LLM.
Les outils basés sur l’IA générative, tels que les chatbots et assistants numériques, sont parmi les plus utilisés, reflétant un engouement croissant pour des solutions capables d’automatiser et de personnaliser les interactions avec les clients. Si 82% des répondants français déclarent utiliser ChatGPT, plus de la moitié utilise des outils d’IA spécifiques, tels que le traitement intelligent des documents (IDP).
Des freins persistants à l’adoption de l’IA
Malgré cette forte adoption, l’étude met en lumière plusieurs inquiétudes. Le risque d’utilisation abusive de l’IA est cité comme l’une des principales préoccupations (38 %). Le manque de talents et de compétences (34 %), les complexités techniques (29 %) et les enjeux de conformité juridique (31 %) sont d’autres freins majeurs. De plus, 49 % des décideurs s’inquiètent des menaces pour la cybersécurité et la protection des données, tandis que 40 % expriment des doutes quant à la fiabilité des informations fournies par l’IA.
Une croissance des investissements en 2025
En dépit de ces défis, 87 % des décideurs informatiques prévoient de renforcer leurs budgets IA pour l’année à venir, 22 % d’entre eux comptent d’ailleurs augmenter leurs investissements de 21 à 30 %. Ces prévisions reflètent la confiance croissante en l’IA, soutenue par des résultats concrets que 80 % des entreprises affirment déjà observer.
Vers une IA responsable ?
Un autre aspect de cette adoption de l’IA est la dimension éthique. Si 81 % des industriels français se disent convaincus de respecter les réglementations en vigueur, seulement 43 % des entreprises ont mis en place des politiques internes claires pour encadrer l’usage de l’IA par leurs équipes de production et de conformité. ABBYY souligne que ce besoin de formaliser des lignes directrices internes devient crucial pour gagner la confiance des utilisateurs et des clients.
Maxime Vermeir, Senior Director of AI Strategy chez ABBYY, commente :
“Il est révélateur que les responsables informatiques de l’industrie préfèrent les petits modèles de langage, probablement en raison des informations erronées associées à l’IA générative. Cela indique une maturation du marché, avec une intégration croissante d’outils spécialisés comme le traitement intelligent des documents (IDP) dans les stratégies d’IA. Les industriels peuvent ainsi combiner l’IA spécialisée avec des solutions basées sur des grands modèles de langage (LLM) pour répondre à des besoins spécifiques, renforçant la confiance. Cependant, le manque d’expertise en mise en œuvre de l’IA demeure une préoccupation, risquant de freiner leur progression. Pour y remédier, ils devraient former leurs employés et recruter des spécialistes en IA, afin de maximiser les avantages de cette technologie”.
Etude ABBYY : la crainte d'être dépassés pousse les industriels français à adopter l'IA
Lors de l’événement annuel TechXchange d’IBM, la société a annoncé la sortie de Granite 3.0, la dernière version de sa famille de modèles de langage (LLM) open source, adaptés aux besoins des entreprises. Granite 3.0 se distingue par son équilibre entre performance, sécurité et rentabilité, répondant aux défis de l’utilisation de LLMs dans des environnements professionnels.
La suite de modèles Granite 3.0 comprend :
Des LLM à usage général : Granite 3.0 8B-Instruct, Granite 3.0 2B-Instruct, Granite 3.0 8B Base, Granite 3.0 2B Base
Granite 3.0 : un modèle d’efficacité et de flexibilité
Granite 3.0 8B et 2B ont été entraînés à partir de 12 000 milliards de jetons de données, provenant de 12 langages naturels et de 116 langages de programmation différents. Les entreprises peuvent les personnaliser avec leurs propres données grâce à la méthode d’alignement InstructLab, introduite par IBM et Red Hat en mai dernier. Elle permet aux entreprises de personnaliser les modèles en utilisant des données synthétiques et des protocoles de formation adaptés à leurs besoins, réduisant ainsi les coûts de trois à vingt-trois fois, et les délais de mise en œuvre.
Les modèles de la famille Granite 3.0 sont adaptés à différentes applications d’IA. Les modèles de base Granite 3.0 8B et 2B, qualifiés de “bourreaux de travail” par IBM, sont conçus pour des tâches variées comme la génération augmentée de récupération (RAG), la classification et la synthèse de données. Ils peuvent être facilement personnalisés avec des données d’entreprise, permettant ainsi aux organisations d’optimiser leurs performances à moindre coût.
Le modèle phare de cette version, Granite 3.0 8B Instruct, un modèle dense optimisé pour les instructions, est destiné à servir de bloc de construction principal pour les flux de travail sophistiqués et les cas d’utilisation basés sur des outils.
En matière de benchmarks académiques et professionnels, Granite 3.0 8B Instruct rivalise avec des modèles concurrents open source de taille similaire, comme Llama 3.1-8B de Meta et Mistral-7B de Mistral AI, tout en se distinguant par ses performances sur des tâches spécifiques à l’entreprise, notamment en cybersécurité. Il a ainsi dominé les évaluations sur RAGBench, un benchmark évaluant la génération augmentée par récupération (RAG) dans des contextes industriels tels que les manuels techniques.
Granite Guardian 3.0 : la sécurité au cœur de l’innovation
Outre ses modèles polyvalents, IBM introduit les modèles Granite 3.0 Guardian, spécialement conçus pour répondre aux besoins critiques de sécurité et de conformité des entreprises. Granite Guardian 3.0 8B et 2B sont des modèles renforcés avec des mécanismes de sécurité intégrés pour minimiser les risques liés aux biais et à l’exploitation malveillante des systèmes d’IA. Grâce à une série de mécanismes de contrôle et de supervision, ces modèles assurent une protection contre les fuites de données sensibles et les réponses inappropriées. Ils peuvent être utilisés pour mettre en œuvre des garde-fous avec n’importe quel modèle d’IA ouvert ou propriétaire.
IBM affirme que Granite Guardian excelle dans les environnements réglementés, où la conformité aux normes de sécurité et de confidentialité est primordiale. Ces modèles sont capables de détecter les anomalies dans les interactions utilisateur et les manipulations malveillantes, ce qui les rend particulièrement adaptés à des secteurs comme la finance, la santé et la défense. Selon ses tests internes, Granite Guardian a surpassé des modèles similaires, comme LLamaGuard de Meta, en matière de détection des risques.
Mixture-of-Experts : performances et rentabilité
La version 3.0 introduit les modèles “Mixture-of-Experts” (MoE), tels que Granite 3.0 3B-A800M Instruct et 1B-A400M Instruct, qui adoptent une approche modulable, où seuls certains experts (sous-modèles spécialisés) sont activés en fonction de la tâche demandée, ce qui les rend très intéressants pour les environnements où les ressources de calcul peuvent être limitées ou coûteuses.
Entraînés sur plus de 10 000 milliards de jetons de données, ces nouveaux modèles MoE Granite sont particulièrement adaptés pour des applications sur l’appareil, des serveurs CPU et des situations nécessitant une latence extrêmement faible.
IBM a également annoncé une mise à jour de ses modèles Granite Time Series pré-entraînés, dont les premières versions ont été publiées au début de l’année. Ces nouveaux modèles, entraînés sur 3 fois plus de données, offrent de solides performances selon les 3 principaux benchmarks de type série temporelle (Time Series), surpassant des modèles 10 fois plus grands de Google, Alibaba et d’autres. Ces modèles mis à jour offrent également une plus grande flexibilité de modélisation grâce à la prise en charge de variables externes et de prévisions glissantes.
Granite 3.0 dans l’écosystème d’IBM
L’introduction de Granite 3.0 s’intègre parfaitement à l’écosystème plus large d’IBM, avec des intégrations optimisées pour certaines de ses plateformes. Watsonx.ai, le produit phare d’IBM dédié à l’IA, s’appuie désormais sur Granite 3.0 pour offrir des solutions avancées aux entreprises cherchant à automatiser leurs processus tout en maintenant un haut niveau de sécurité et de transparence.
IBM a également mis en avant la compatibilité de Granite 3.0 avec ses outils de gestion des modèles et des données, permettant aux entreprises de surveiller et d’ajuster en continu leurs modèles pour améliorer la précision et la pertinence. L’intégration avec des outils comme Watsonx.data et Watsonx.governance garantit que les données sont gérées et utilisées de manière responsable tout au long du cycle de vie des modèles.
IBM continue d’améliorer Granite avec des extensions prévues pour la fin 2024, comme l’augmentation de la fenêtre de contexte à 128 000 jetons et l’ajout de capacités multimodales. Tous les modèles Granite 3.0 sont entraînés sur l’infrastructure Blue Vela d’IBM, qui fonctionne à 100 % grâce à des sources d’énergie renouvelable. Ce choix s’inscrit dans l’engagement croissant d’IBM à intégrer des pratiques durables dans ses processus de développement technologique.
Disponibilité des modèles Granite 3.0
Les modèles Granite 3.0 et les modèles Time Series mis à jour sont distribués sous la licence Apache 2.0 et peuvent être téléchargés sur HuggingFace, renforçant l’engagement d’IBM envers l’open source et la transparence.
Les variantes d’instruction des nouveaux modèles de langage Granite 3.0 8B et 2B et les modèles Granite Guardian 3.0 8B et 2B sont disponibles dès aujourd’hui pour une utilisation commerciale sur la plateforme watsonx d’IBM. Une sélection des modèles Granite 3.0 sera également disponible en tant que microservices NVIDIA NIM et via les intégrations Vertex AI Model Garden de Google Cloud avec HuggingFace.
Pour faciliter le choix et l’utilisation des développeurs et soutenir les déploiements locaux et à la périphérie (edge), un ensemble organisé de modèles Granite 3.0 est également disponible sur Ollama et Replicate.
Les modèles sont également disponibles sur les plateformes de partenaires d’IBM, tels qu’AWS, Docker, Domo, Qualcomm Technologies, Salesforce ou SAP.
Open source : IBM dévoile Granite 3.0, sa nouvelle génération de LLMs optimisés pour les entreprises
LightOn, une entreprise européenne spécialisée dans l’IA générative, a franchi une étape importante en obtenant l’approbation de l’Autorité des marchés financiers (AMF) pour son introduction en Bourse sur Euronext Growth Paris. Fondée en 2016 par Igor Carron et Laurent Daudet, LightOn s’est démarquée en développant des solutions d’IA générative adaptées aux besoins des entreprises, visant à améliorer leur productivité. Ses produits phares, Forge et Paradigm, sont utilisés par des entreprises en Europe, aux États-Unis et dans la région EMEA.
Après avoir lancé en 2020 son tout premier co-processeur photonique, LightOn a entrepris de développer les premiers grands modèles de langage dédiés aux langues européennes, un défi dans le domaine encore naissant de l’IA générative.
Au départ, l’entraînement des grands modèles de langage faisait partie des applications possibles pour le processeur photonique de LightOn. Très vite, l’équipe se passionne pour cette nouvelle génération d’IA, encore méconnue en France, élabore et entraîne ses propres modèles. En 2020, elle met en accès libre son premier modèle français à travers une interface simple de génération de texte : PAGnol. En 2022, après une année et demi de travail intensif, elle a mis au point VLM-4, une suite de grands modèles de langage dans un premier temps en 5 langues européennes : anglais, allemand, espagnol, français et italien.
Avec une équipe de 41 collaborateurs, LightOn, plutôt que de se concentrer sur des applications grand public, cible le secteur professionnel avec une offre spécialisée. Les solutions développées par l’entreprise permettent d’automatiser des tâches complexes et d’optimiser les processus métier.
Une version avancée d’Alfred-40B-1023, la seconde itération d’Alfred-40B-0723, un modèle de langage open source basé sur Falcon-40B, alimente Paradigm, sa plateforme d’IA générative dédiée aux entreprises et aux services publics, qui peut être directement intégrée dans les infrastructures existantes, garantissant ainsi la sécurité des données des organisations utilisatrices. LightOn continue d’affiner cette solution, qui a été adoptée par des acteurs de divers secteurs, notamment le SEO, la défense, la santé et l’aéronautique, grâce à des mises à jour régulières. Elle collabore également étroitement avec des entreprises pour concevoir des cas d’usage personnalisés, en s’appuyant sur Forge, une autre solution logicielle qu’elle commercialise.
Stratégies de partenariat et expansion future
La stratégie de LightOn repose également sur des partenariats avec des entreprises telles qu’Orange Business et Hewlett Packard Enterprise, pour étendre son influence dans l’écosystème technologique européen. Des négociations avancées sont d’ailleurs en cours avec d’autres acteurs des secteurs des infrastructures, du matériel informatique, du cloud et des services IT et pourraient aboutir à de nouveaux partenariats dans les trimestres à venir.
L’augmentation de capital envisagée via l’introduction en Bourse, hors clauses d’extension et de surallocation le cas échéant, est d’environ 10 millions d’euros, LightOn a déjà reçu un engagement de souscription de la part d’Axon Partners Group pour un montant de 3 M€. Elle permettra de soutenir la croissance de l’entreprise, qui ambitionne d’atteindre un chiffre d’affaires de 40 millions d’euros et des revenus annuels récurrents de 35 millions d’euros d’ici 2027.
Le choix d’une entrée sur le marché boursier reflète une volonté de la société d’accélérer son expansion à l’international, avec une priorité pour l’Europe et le Moyen-Orient, tout en se maintenant à la pointe des dernières avancées technologiques dans son domaine.
Alors que la demande pour des solutions d’IA personnalisées continue de croître, notamment dans les secteurs des services publics et des entreprises, LightOn entend se positionner comme un acteur de référence sur ce marché. L’introduction en Bourse pourrait offrir à l’entreprise les moyens financiers de rester compétitive dans un secteur en pleine évolution.
Igor Carron et Laurent Daudet, co-PDG et co-fondateurs de LightOn, commentent :
“L’IA générative va transformer en profondeur les usages des entreprises. Les promesses de cette technologie révolutionnaire sont immenses et le marché mondial adressable est colossal. À la pointe de son secteur sur la technologie, LightOn est une entreprise commerciale avec des solutions déjà au cœur des grandes entreprises privées et publiques. Mais l’aventure ne fait que commencer. Le décollage de notre marché se confirme à un rythme qui dépasse nos attentes. Nos partenariats stratégiques avec Orange Business et Hewlett Packard Enterprise, vont nous permettre de démultiplier notre conquête commerciale et de prendre rapidement des parts de marché pour nous positionner comme un partenaire privilégié des entreprises en Europe et au-delà en matière d’IA générative”.
Concluant :
“Fort de la demande que nous enregistrons actuellement et de notre solide dynamique commerciale en cours, nous sommes aujourd’hui prêts à nous fixer des objectifs ambitieux : atteindre environ 40 M€ de chiffre d’affaires, associé à une marge d’EBITDA d’environ 40% du chiffre d’affaires et environ 35 M€ d’ARR d’ici 2027. C’est pour accompagner ce développement rapide et accroître nos positions que nous annonçons aujourd’hui le lancement de notre projet d’Introduction en Bourse”.
LightOn se prépare à entrer en Bourse sur Euronext Growth Paris pour renforcer sa position dans l'IA générative
Les modèles de langage de petite taille (SLM) sont une alternative intéressante aux LLMs pour les entreprises qui peuvent les exploiter à moindre coût pour des tâches spécifiques. Microsoft après avoir introduit le SLM Phi-1 en juin 2023 et présenté le 23 avril dernier la famille de modèles open source Phi-3, dévoile à présent les modèles Phi-3,5 : Phi-3.5-mini-instruct, Phi-3.5-MoE-instruct, et Phi-3.5-vision-instruct.
Chacun de ces modèles est optimisé pour des tâches spécifiques, tout en partageant une longueur de contexte de 128 000 jetons, permettant une manipulation efficace des données complexes.
Phi-3.5-mini-instruct : un modèle compact et puissant pour environnements restreints
Le Phi-3.5-mini-instructest le plus petit modèle de la série, conçu pour offrir des performances robustes dans des environnements où les ressources informatiques sont limitées. Avec 3,8 milliards de paramètres, ce modèle est parfaitement adapté aux tâches nécessitant un raisonnement logique solide, telles que la génération de code et la résolution de problèmes mathématiques.
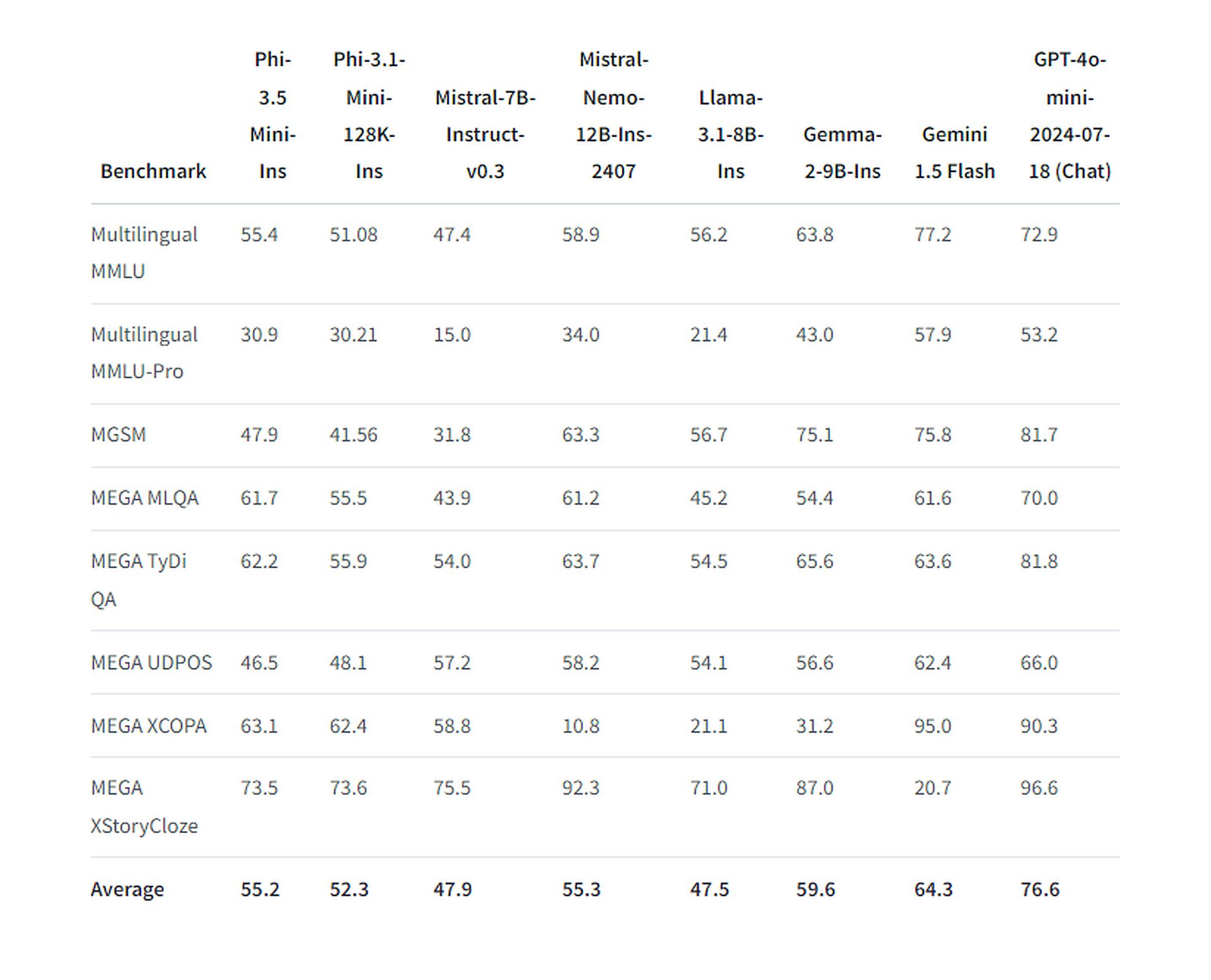
Malgré sa taille réduite, ce modèle a été entraîné sur un impressionnant ensemble de 3,4 billions de jetons à l’aide de 512 GPU H100-80G pendant 10 jours. Les performances de Phi-3.5 Mini Instruct dans les tâches conversationnelles multilingues et multi-tours sont remarquables. Le modèle est compétitif avec d’autres modèles ouverts beaucoup plus grands tels que Llama-3.1-8B-instruct, Mistral-7B-instruct-v0.3 et Mistral-Nemo-12B-instruct-2407. Il a notamment surpassé Llama-3.1-8B-instruct et Mistral-7B-instruct-v0.3 dans le benchmark RepoQA (compréhension du code à contexte long).
Phi-3.5-MoE-instruct : une architecture de mélange d’experts
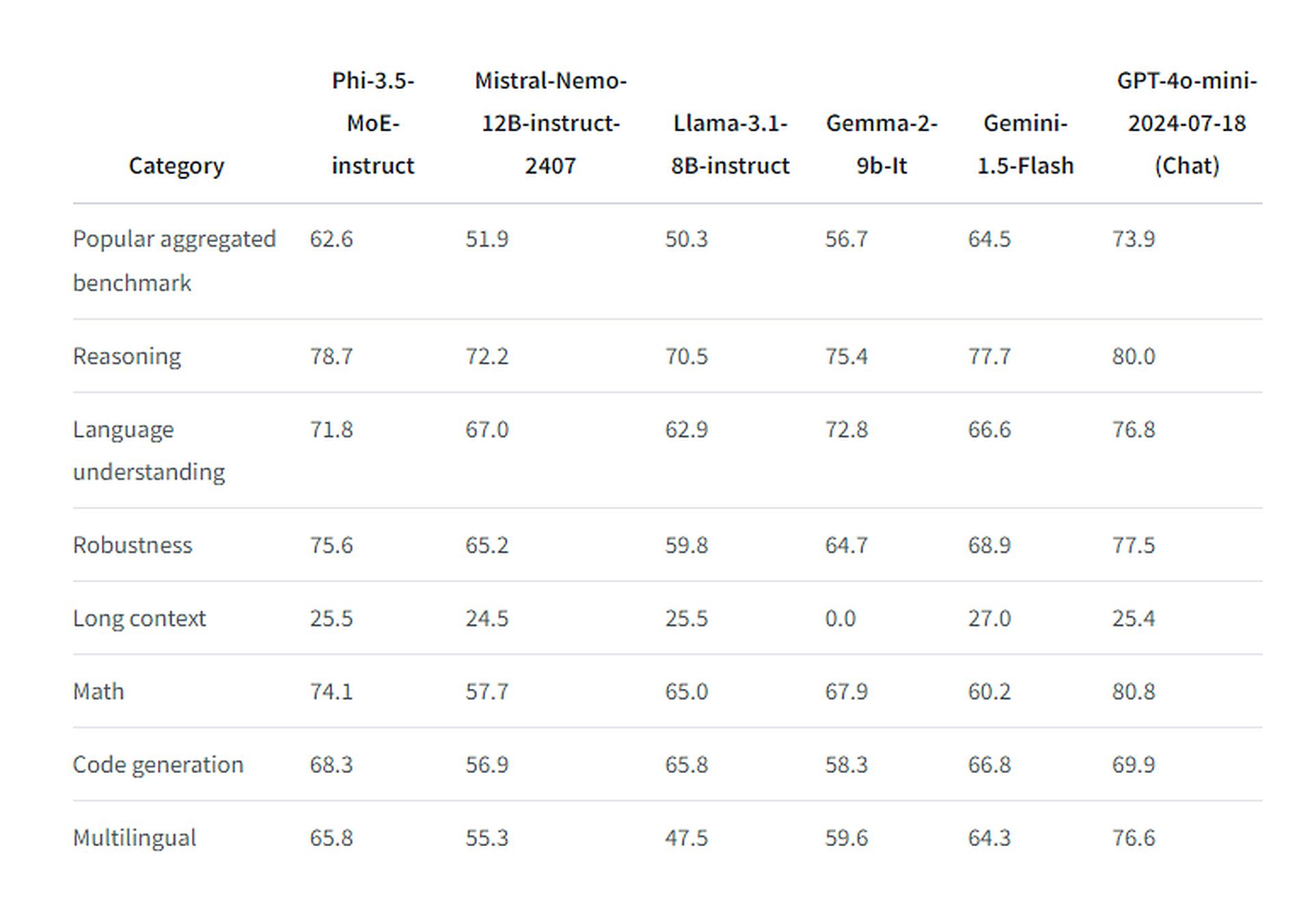
Le modèle Phi-3.5-MoE(Mixture of Experts) représente une avancée significative dans l’architecture de l’IA. Ce modèle utilise une approche sophistiquée qui active différents “experts” en fonction de la tâche à accomplir, optimisant ainsi les performances pour des tâches spécifiques. Avec 42 milliards de paramètres, dont 6,6 milliards activés à chaque utilisation, le Phi-3.5 MoE est conçu pour gérer des tâches de raisonnement complexes, la compréhension de code et le traitement multilingue.
Il prend en charge les langues suivantes : Allemand, Anglais, Arabe, Chinois, Coréen, Danois, Espagnol, Finnois, Français, Hébreu, Hongrois, Italien, Japonais, Norvégien, Néerlandais, Polonais, Portugais, Russe, Suédois, Thaï, Turc et Ukrainien.
Entraîné sur 4,9 billions de jetons, dont 10 % multilingues, en utilisant 512 GPU H100-80G pendant 23 jours, le modèle MoE a montré une supériorité notable dans les tests de performance spécifiques. Il a surpassé les modèles plus grands Llama 3.1-8B-instruct, Gemma 2-9B-It et Gemini 1.5-Flash mais s’est incliné face à GPT-4o-mini d’OpenAI, dans la majorité des cas. Cependant, dans le test MMLU (Massive Multitask Language Understanding) à 5 coups, il a réussi à prendre l’avantage sur ce dernier.
Microsoft commente :
“Il est encore fondamentalement limité par sa taille pour certaines tâches. Le modèle n’a tout simplement pas la capacité de stocker trop de connaissances factuelles, par conséquent, les utilisateurs peuvent rencontrer des inexactitudes factuelles. Cependant, nous pensons qu’une telle faiblesse peut être résolue en augmentant Phi-3.5 avec un moteur de recherche, en particulier lors de l’utilisation du modèle sous les paramètres RAG”.
Le modèle a fait l’objet d’un processus d’amélioration rigoureux, intégrant un réglage fin supervisé, une optimisation des politiques proximales et une optimisation des préférences directes pour garantir une adhésion précise aux instructions et des mesures de sécurité robustes.
Phi-3.5-vision-instruct : pour les tâches multimodales
LePhi-3.5-vision-instructest conçu pour les tâches multimodales, intégrant à la fois des données textuelles et visuelles. Avec 4,15 milliards de paramètres, ce modèle est spécialement adapté pour des applications telles que la reconnaissance optique de caractères (OCR), la compréhension de graphiques et de tableaux, et le résumé vidéo.
Il a été entraîné sur 500 milliards de jetons avec 256 GPU A100-80G sur une période de 6 jours. Son aptitude à traiter et à intégrer des données complexes, combinée à sa capacité à gérer plusieurs images, en fait un outil extrêmement polyvalent pour les tâches nécessitant une analyse détaillée des informations visuelles et textuelles.
Open source pour une adoption généralisée
Les trois modèles de la série Phi-3.5 sont disponibles sous licence MIT, ce qui permet aux développeurs de les utiliser, de les modifier et de les distribuer sans restriction. Ils sont disponibles sur Hugging Face, Phi-3.5 Vision Instruct est également accessible via Azure AI Studio.
Phi-3.5 Microsoft présente la dernière génération de ses SLM, optimisée pour des tâches spécifiques
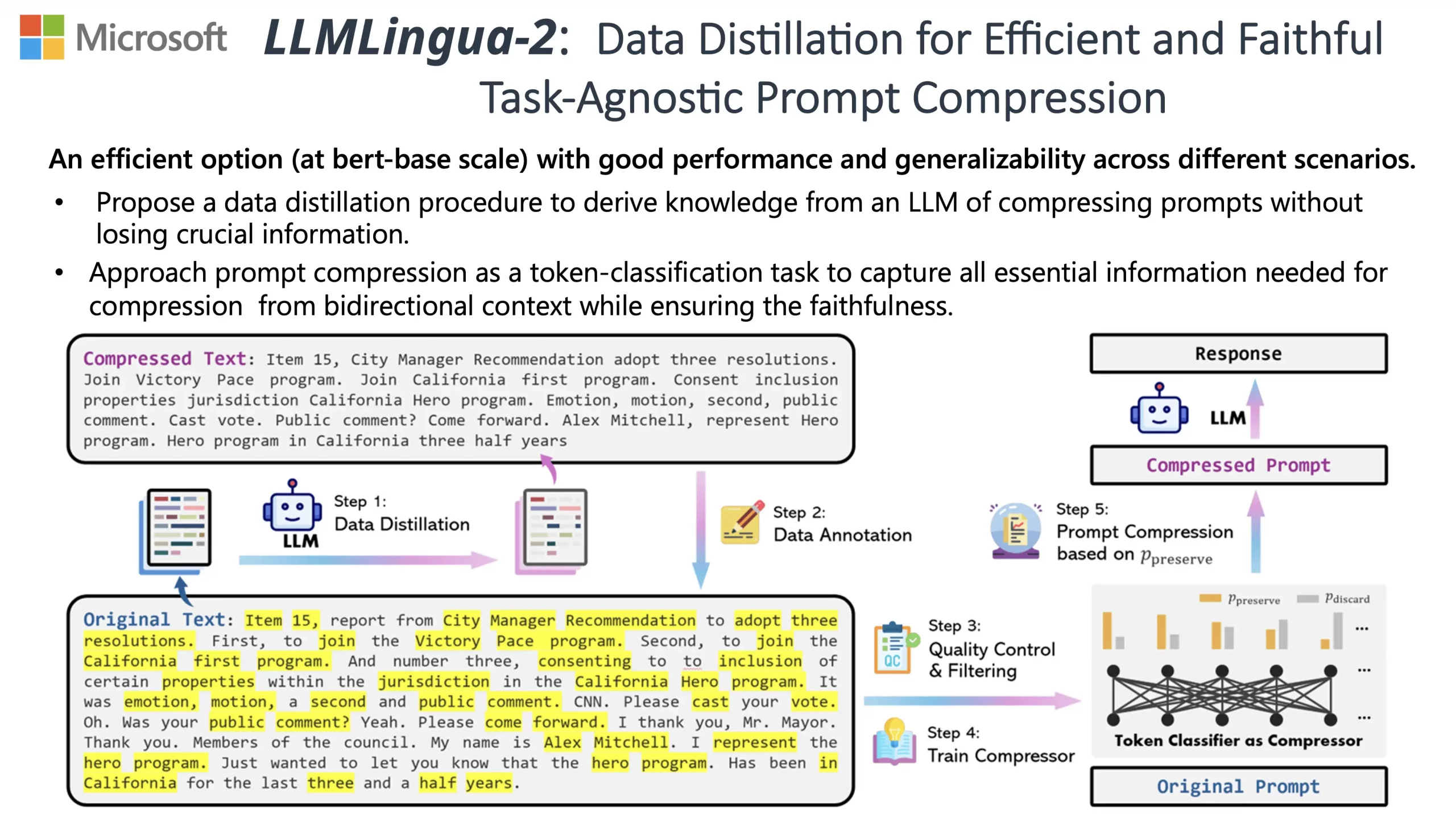
Vous êtes-vous déjà retrouvé frustré par les limites de tokens lorsque vous demandiez à ChatGPT de résumer de longs textes ? Ou découragé par les coûts élevés de l’API GPT-3.5/4 malgré d’excellents résultats ? Si c’est le cas, LLMLingua est fait pour vous !
Développé par des chercheurs de Microsoft, LLMLingua-2 est un outil révolutionnaire de compression de prompts qui permet d’accélérer l’inférence des grands modèles de langage (LLM) comme GPT-3 et GPT-4. Grâce à des techniques avancées d’identification et de suppression des tokens non essentiels, il peut réduire jusqu’à 20 fois la taille des prompts, tout en préservant les performances des modèles.
Que vous soyez un développeur cherchant à optimiser ses coûts d’API ou un utilisateur souhaitant dépasser les limites de contexte, LLMLingua vous offre de nombreux avantages :
💰 Réduction des coûts : En compressant à la fois les prompts et les réponses générées, LLMLingua permet de réaliser des économies significatives sur votre facture d’API.
📝 Support de contextes étendus : Fini le casse-tête du « perdu au milieu » ! LLMLingua gère efficacement les longs contextes et booste les performances globales.
⚖️ Robustesse : Pas besoin d’entraînement supplémentaire pour les LLM. LLMLingua fonctionne de manière transparente.
🕵️ Préservation des connaissances : Toutes les informations clés des prompts originaux, comme l’apprentissage en contexte et le raisonnement, sont conservées.
📜 Compression du cache KV : Le processus d’inférence est accéléré grâce à l’optimisation du cache clé-valeur.
🪃 Récupération complète : GPT-4 est capable de reconstituer l’intégralité des informations à partir des prompts compressés. Bluffant !
Prenons un exemple simple et imaginons que vous vouliez compresser le prompt suivant avec LLMLingua :
python from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
prompt = "Sam a acheté une douzaine de boîtes contenant chacune 30 surligneurs, pour 10 $ chacune..."
compressed_prompt = llm_lingua.compress_prompt(prompt)
print(compressed_prompt)
Et voilà le travail ! En quelques lignes de code, vous obtenez un prompt compressé prêt à être envoyé à votre modèle favori :
Sam acheté boîtes contenant chacune 30 surligneurs, 10 $ chacune.
Avec un taux de compression de 11,2x, le nombre de tokens passe de 2365 à seulement 211 ! Et ce n’est qu’un début. Sur des exemples plus complexes comme les prompts Chain-of-Thought, LLMLingua maintient des performances similaires avec un taux de compression allant jusqu’à 20x.
Alors bien sûr, pour l’avoir bien testé, faut quand même comprendre que vous n’obtiendrez pas forcement un résultat identique entre le prompte compressé et celui non compressé mais pour un gain de 60 / 70 voire 80%, le résultat généré à partir du prompt compressé reste précis à hauteur de 70 / 80 %, ce qui est très bien.
Pour démarrer avec LLMLingua, rien de plus simple. Installez le package avec pip :
pip install llmlingua
Puis laissez libre cours à votre créativité ! Que vous soyez un adepte du Retrieval Augmented Generation (RAG), des réunions en ligne, du Chain-of-Thought ou même du code, LLMLingua saura répondre à vos besoins. De nombreux exemples et une documentation complète sont à votre disposition pour vous guider.
Perso, je l’ai testé sur de longs prompts que j’avais dans mes scripts, avec Claude3 d’ailleurs et pas ChatGPT et le résultat est top !
DeepL, entreprise technologique basée en Allemagne, un des leaders mondiaux dans le domaine de l’IA linguistique, a récemment publié les résultats d’une étude réalisée par Forrester Consulting, mettant en lumière l’impact commercial positif de son outil de traduction IA, DeepL Translator.
Basée à Cologne, DeepL a été fondée en 2009 par Jaroslaw Kutylowski et a commencé à travailler en 2016 sur la première version de DeepL Translator. En 2020, le système de traduction intègre ses nombreuses avancées en matière d’IA, notamment dans le domaine de l’architecture des réseaux neuronaux, améliorant la qualité des traductions.
Continuellement évalué et amélioré pour garantir une qualité optimale, il offre aux entreprises la possibilité de communiquer efficacement à l’échelle internationale, sans les obstacles des barrières linguistiques.
L’étude “The Total Economic Impact™ of DeepL”
Afin de savoir quel était son impact sur les résultats de ses clients, DeepL a demandé à Forrester Consulting d’interroger des multinationales pour connaître le rôle de son outil de traduction sur leur activité.
Pour analyser de manière plus approfondie les avantages, les risques, les coûts et la flexibilité de l’utilisation de DeepL Translator dans un contexte réel et représentatif, Forrester Consulting a choisi quatre entreprises représentatives de différents secteurs (énergie, services financiers, services juridiques, et secteur pharmaceutique).
Basées aux États‑Unis ou en Europe, ces organisations, qui comptent entre 1 600 et 40 000 salariés, se déploient ou font du commerce à l’international et génèrent entre 365 millions et 33,7 milliards d’euros de revenus.
Les principaux résultats de l’étude
L’étude met non seulement en évidence l’impact commercial positif des outils de traduction IA de DeepL, tous secteurs d’activité confondus, mais démontre également que la traduction est l’un des domaines les plus stratégiques de la mise en œuvre de l’IA pour les entreprises qui cherchent à augmenter leur chiffre d’affaires et à pénétrer plus rapidement de nouveaux marchés.
Les chiffres de l’étude parlent d’eux‑mêmes : les traductions IA de DeepL ont permis aux organisations interrogées de faire de précieuses économies (en temps et en ressources), et de dégager un retour sur investissement très positif.
Les principaux bénéfices rapportés sont :
Une réduction de 90 % du temps de traduction des documents internes ;
Un retour sur investissement (ROI) de 345 % sur trois ans ;
Une réduction de 50 % de la charge de travail de traduction ;
Des économies de 227 430 euros sur trois ans dans le domaine des flux de travail ;
Des économies d’efficacité de 2,8 millions d’euros sur trois ans.
Ces résultats soulignent l’efficacité de l’IA linguistique de DeepL et ses avantages tangibles en termes de réduction des coûts, d’amélioration de l’efficacité opérationnelle et de création de valeur pour les entreprises.
Open WebUI débarque pour changer notre façon d’interagir avec Ollama grâce à une interface graphique intuitive et ergonomique ! Parce que l’IA, c’est cool, mais si c’est simple à utiliser, c’est encore mieux. Ollama pour rappel, c’est un outil qui permet de faire tourner des LLM en local et qui s’utilise soit via du code, soit directement en ligne de commande.
Avec Open WebUI, vous allez enfin avoir une interface web personnalisable avec votre thème, sombre pour les hackers en herbe ou clair pour les âmes sensibles, dans la langue de votre choix, de l’anglais au klingon en passant par le français, et vous pourrez ainsi causer avec Ollama comme si vous étiez sur ChatGPT. Avec le support de Markdown, de LaTeX et de la coloration syntaxique, vous pourrez même lui faire cracher du code et des formules mathématiques comme jamais.
Open WebUI permet même d’utiliser plusieurs modèles en parallèle, comparer leurs réponses, et même les faire discuter entre eux… Et si vous voulez de l’interaction plus poussée, lâchez-vous avec les fonctionnalités de Récupération Augmentée (RAG). Vous pourrez intégrer des documents externes dans vos conversations et même aller les chercher directement sur le web grâce à une fonction de navigation intégrée.
Avec l’outil de création de fichiers modèle (modelfiles), vous pouvez également définir des agents conversationnels sur mesure et les partager avec la communauté Open WebUI.
Bien sûr, comme tout bon logiciel qui se respecte, Open WebUI gère la reconnaissance vocale, la synthèse Text-to-Speech et même la génération d’images avec DALL-E et d’autres systèmes compatibles. Cadeau bonux, l’intégration avec les API compatibles OpenAI, pour encore plus de possibilités déjantées.
C’est open source, c’est puissant, c’est customisable à outrance alors que vous soyez un champion du dev ou comme moi, juste un curieux qui veut s’amuser avec l’IA, vous allez vous régaler.
Avant de vous lancer dans l’installation d’Open WebUI, assurez-vous d’avoir les prérequis suivants :
Docker installé sur votre machine
Une URL de base pour Ollama (OLLAMA_BASE_URL) correctement configurée
Pour configurer l’URL de base d’Ollama, vous pouvez soit la définir en tant que variable d’environnement, soit la spécifier dans un fichier de configuration dédié.
Une fois les prérequis remplis, vous pouvez procéder à l’installation d’Open WebUI en utilisant Docker :
docker run -d -p 3000:8080 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Cette commande va télécharger l’image Docker d’Open WebUI et lancer un conteneur accessible sur http://localhost:3000.
llamafile est un projet complètement barré qui va vous permettre de transformer des modèles de langage en exécutables. Derrière se cache en fait la fusion de deux projets bien badass : llama.cpp, un framework open source de chatbot IA, et Cosmopolitan Libc, une libc portable pour compiler des programmes C multiplateformes. En combinant astucieusement ces deux technos, les petits gars de Mozilla ont réussi à pondre un outil qui transforme les poids de modèles de langage naturel en binaires exécutables.
Imaginez un peu, vous avez un modèle de langage qui pèse dans les 4 gigas, dans un format .gguf (un format couramment utilisé pour les poids de LLM). Et bien avec llamafile, vous pouvez le transformer en un exécutable standalone qui fonctionnera directement sur le système sur lequel il est sans avoir besoin d’installer quoi que ce soit. Ça va permettre de démocratiser l’utilisation et la diffusion des LLM.
Et niveau portabilité, c’est le feu puisque ça tourne sur six OS, de Windows à FreeBSD en passant par macOS. Les devs ont bien bossé pour que ça passe partout, en résolvant des trucs bien crados comme le support des GPU et de dlopen() dans Cosmopolitan et croyez-moi (enfin, croyez-les) ça n’a pas été une mince affaire !
Niveau perf aussi c’est du brutal ! Sur Linux llamafile utilise pledge() et SECCOMP pour sandboxer le bousin et empêcher les accès fichiers non désirés et avec les derniers patchs de Justine Tunney, la perf CPU pour l’inférence en local a pris un boost de malade du genre 10 fois plus rapide qu’avant. Même sur un Raspberry Pi on peut faire tourner des petits modèles à une vitesse honnête.
Allez, assez parlé, passons à la pratique !
Voici comment tester vous-même un llamafile en un rien de temps :
Téléchargez l’exemple de llamafile pour le modèle LLaVA (licence : LLaMA 2, OpenAI) : llava-v1.5-7b-q4.llamafile (3,97 Go). LLaVA est un nouveau LLM qui peut non seulement discuter, mais aussi analyser des images que vous uploadez. Avec llamafile, tout se passe en local, vos données ne quittent jamais votre PC.
Ouvrez le terminal de votre ordinateur.
Si vous êtes sous macOS, Linux ou BSD, vous devrez autoriser l’exécution de ce nouveau fichier. (À faire une seule fois) : chmod +x llava-v1.5-7b-q4.llamafile
Sous Windows, renommez simplement le fichier en ajoutant « .exe » à la fin.
Lancez le llamafile, par exemple : ./llava-v1.5-7b-q4.llamafile
Votre navigateur devrait s’ouvrir automatiquement sur une interface de chat. (Sinon, ouvrez-le et allez sur http://localhost:8080)
Quand vous avez fini, retournez dans le terminal et faites Ctrl-C pour arrêter llamafile.
Évidemment, Mozilla ne compte pas s’arrêter là et continue de bosser comme des dingues pour suivre le rythme des nouveaux modèles qui sortent et avec le support des dernières architectures dès leur sortie.
Il est même prévu qu’on puisse bientôt générer nos propres llamafiles en un seul clic ! D’ailleurs, Hugging Face est déjà dans la boucle pour héberger tout ce petit monde. Bref, je vous le dis, les amis, llamafileest un projet à suivre absolument !
Les grands modèles de langage (LLM) présentent des capacités impressionnantes dans différents domaines mais les modèles plus petits (SLM) sont une alternative intéressante pour les entreprises qui peuvent les exploiter à moindre coût pour des tâches spécifiques. Microsoft, qui a introduit le SLM Phi-1 en juin 2023, a présenté le 23 avril dernier la famille de modèles ouverts Phi-3. Le plus petit d’entre eux, Phi-3 mini, d’ores et déjà disponible, compte 3,8 milliards de paramètres et, grâce à sa petite taille, peut être déployé en local sur un téléphone ou un ordinateur.
Microsoft présente les modèles Phi-3 comme “les modèles de langage de petite taille les plus performants et les plus rentables disponibles”.
Phi-3 Mini est un modèle de transformateur avec décodeur dense, affiné grâce au fine-tuning supervisé (SFT) et l’optimisation directe des préférences (DPO) pour garantir l’alignement avec les préférences humaines et les directives de sécurité. Il est disponible sur Azure AI Studio, Hugging Face et Ollama.
Il a été entraîné pendant sept jours sur 512 GPU NVIDIA H100 Tensor Core, NVIDIA nous a d’ailleurs précisé qu’il était possible de l’essayer sur ai.nvidia.com où il sera packagé en tant que NVIDIA NIM, “un microservice avec une interface de programmation d’application standard qui peut être déployé n’importe où”.
Dans leur rapport technique, les chercheurs expliquent que “L’innovation réside entièrement dans notre jeu de données pour l’entraînement, une version agrandie de celle utilisée pour PHI-2, composé de données web fortement filtrées et de données synthétiques“.
Le modèle, entraîné sur 3,3 trillions de jetons, a également été aligné pour la robustesse, la sécurité et le format de chat. Sa fenêtre contextuelle, qui peut aller de 4 000 jusqu’à 128 000 jetons, lui permet d’assimiler et de raisonner sur des contenus textuels volumineux (documents, pages Web, code…). Selon Microsoft, Phi-3-mini démontre de solides capacités de raisonnement et de logique, ce qui en fait un bon candidat pour les tâches analytiques.
Des performances solides malgré une petite taille
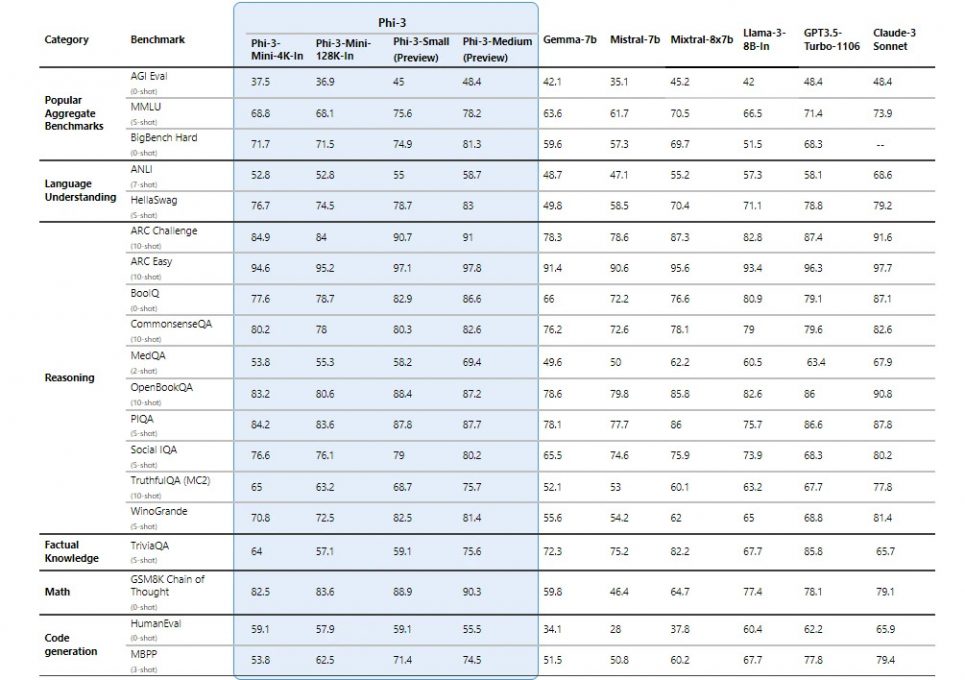
Microsoft a partagé dans son blog les performances de Phi-3 mini, mais également celles de Phi-3-small (7B) et Phi-3-medium (14B) qui seront prochainement disponibles et ont été entraînés sur 4,8 trillions de tokens.
Les performances des modèles Phi-3 ont été comparées à celles de Phi-2, Mistral-7b, Gemma-7B, Llama-3-instruct-8b, Mixtral-8x7b, GPT-3.5 Turbo et Claude-3 Sonnet. Tous les chiffres déclarés sont produits avec le même pipeline afin qu’ils soient effectivement comparables.
Phi-3-mini surpasse Gemma-7B et Mistral-7B sur certains benchmarks de référence comme MMLU, tandis que Phi-3-small et Phi-3-medium, nettement plus performants, surpassent les modèles beaucoup plus grands, y compris GPT-3.5 Turbo. Cependant, du fait de leur petite taille, les modèles Phi-3 sont moins compétitifs pour les tâches axées sur les connaissances factuelles, telles que celles évaluées dans TriviaQA.
Toutefois, leurs capacités dans de nombreux autres domaines, les rendent particulièrement utiles dans des scénarios où la taille du modèle et les ressources disponibles sont des facteurs critiques, comme dans les environnements à ressources limitées ou les applications nécessitant des temps de réponse rapides.
PyTorch, le framework chouchou des bidouilleurs d’IA, vient de nous pondre un petit truc cool : Torchtune ! 💎 Cette nouvelle bibliothèque native, encore en phase alpha mais déjà disponible en open-source sur GitHub, va vous permettre de fine-tuner les gros modèles de langage (LLM) comme un pro, sans vous prendre la tête.
Torchtune est donc une boîte à outils hyper flexible et modulaire qui va vous permettre de vous éclater à customiser des modèles pour vos propres besoins, le tout avec des recettes mémoire efficaces qui tournent même sur une bête carte graphique de gamer, comme les NVidia 3090/4090.
Son secret ?
Une architecture bien pensée qui mise sur l’interopérabilité avec l’écosystème des LLM, qu’ils soient open-source ou non. Concrètement, ça veut dire que vous allez pouvoir brancher Torchtune à tout un tas d’outils et de frameworks que vous adorez déjà, comme Hugging Face 🤗, PyTorch FSDP 🪢, Weights & Biases 📈, et plein d’autres.
Grâce à des recettes simples et bien documentées pour les modèles populaires comme Llama 3, Mistral ou Gemma 7B, même les débutants vont pouvoir se lancer dans l’aventure sans flipper. Bon OK, il faudra quand même un peu de bagage en PyTorch et en LLM, mais rien d’insurmontable ! Et si vous êtes un pro, vous allez pouvoir hacker le code à volonté pour l’adapter à vos besoins spécifiques.
Rien de plus simple, mon cher Watson ! Il vous suffit d’installer la dernière version stable de PyTorch (2.2.2 au moment où j’écris ces lignes), puis de télécharger Torchtune depuis PyPI avec un petit
pip install torchtune
Et voilà, vous êtes prêt à en découdre avec les LLM !
Pour vous faire les dents, je vous conseille de jeter un œil au tutoriel sur le fine-tuning de Llama2 7B. C’est le parfait point de départ pour comprendre comment Torchtune fonctionne et comment l’utiliser pour vos propres projets.
En gros, ça se passe en 4 étapes :
Téléchargez le modèle pré-entraîné et le tokenizer depuis Hugging Face Hub avec tune download.
Choisissez une recette de fine-tuning (LoRA, QLoRA, full…) et customisez-la avec un fichier de config en YAML.
Lancez l’entraînement avec tune run en précisant votre recette et votre config. Vous pouvez même faire du multi-GPU avec torchrun !
Admirez le résultat et testez votre modèle fine-tuné avec une inférence locale. Si tout se passe bien, exportez-le avec ExecuTorch pour le déployer en prod, ou utilisez les API de quantification de Torchao pour l’exporter en int4 ou int8 et l’utiliser sur mobile ou en edge.
Facile, non ? 😄
Bon OK, j’avoue, j’ai un peu simplifié. En vrai, il y a pas mal de subtilités et de paramètres à régler pour obtenir les meilleurs résultats, comme le learning rate, le nombre d’époques, la taille du batch, le ratio de LoRA, et tout un tas d’autres trucs, mais c’est justement sa flexibilité qui vous permet d’expérimenter à l’infini pour trouver la combinaison parfaite.
Bref, si vous êtes dev et que vous aimez jouer avec les LLM c’est à tester.
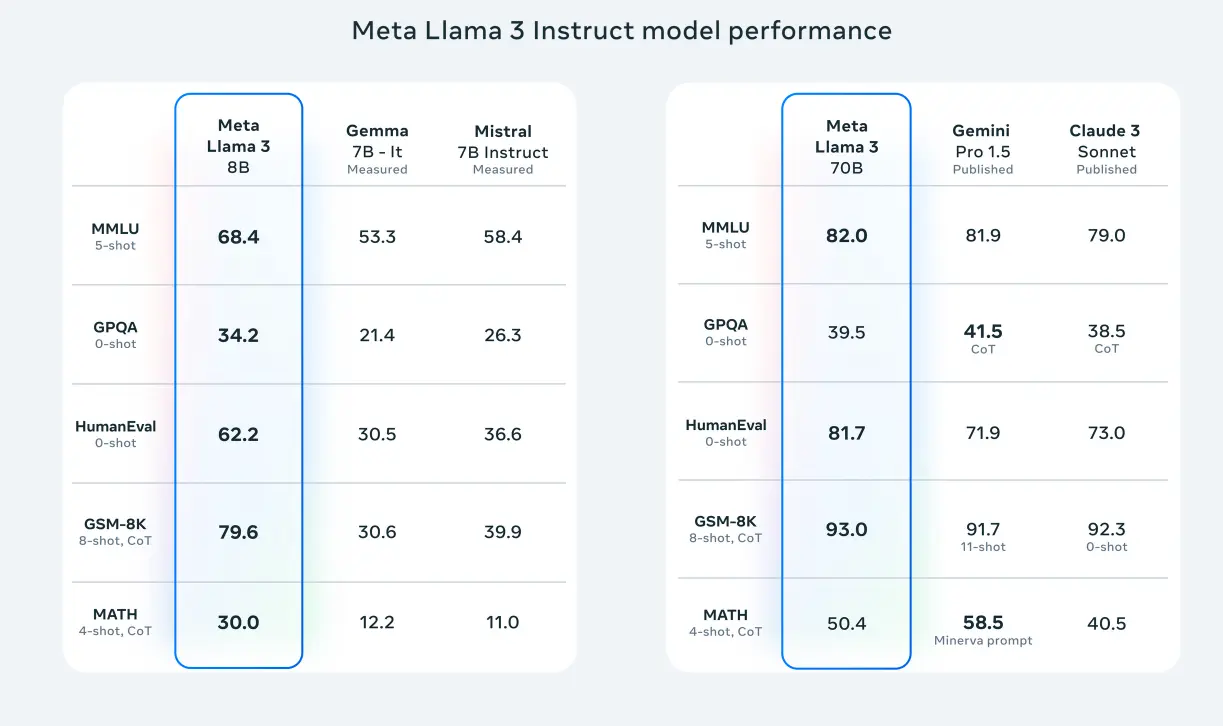
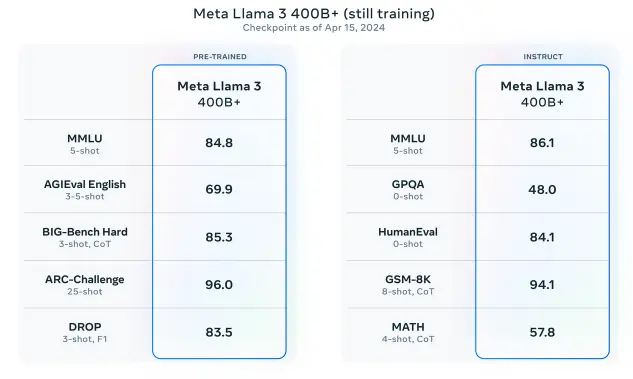
Accrochez-vous à vos claviers, car Meta vient de lâcher dans la nature une nouvelle créature nommée Llama 3. Oui, vous avez bien compris, je parle de la dernière génération de modèles de langage « open source » (ou presque, on y reviendra) de la société de Mark Zuckerberg.
Si vous pensiez que ChatGPT, Claude ou Mistral étaient les rois de la savane, attendez de voir débarquer ces nouveaux lamas survitaminés ! Avec des versions allant de 8 à 400 milliards de paramètres (pour les non-initiés, disons que c’est l’équivalent de leur QI 🧠), les Llama 3 atomisent littéralement la concurrence sur de nombreux benchmarks standards, que ce soit en termes de connaissances générales, de compréhension, de maths, de raisonnement ou de génération de code.
Mais qu’est-ce qui fait de Llama 3 un tel monstre par rapport à son petit frère Llama 2 ? Déjà, un entraînement de folie à base de 15 000 milliards de tokens (7 fois plus que Llama 2 !) pompé depuis le web (!!), avec beaucoup plus de code et de données non-anglaises pour préparer le terrain à une IA multilingue. Ajoutez à ça des techniques de parallélisation à gogo pendant la phase de pré-entraînement, et vous obtenez des lamas dopés qui apprennent à une vitesse supersonique.
Et ce n’est pas tout ! Les Llama 3 ont suivi un programme d’éducation complet, avec du fine-tuning à base de rejection sampling, de PPO et de DPO (si vous ne connaissez pas ces acronymes, ne vous inquiétez pas, moi non plus 😅). Résultat : des modèles ultra-fiables qui refusent rarement une tâche, font preuve d’un alignement exemplaire et sont capables de suivre des instructions complexes sans sourciller. Bref, ce sont des cracks en raisonnement et en génération de code !
Mais au fait, comment on met la main sur ces petites bêtes ? Facile, il suffit de se rendre sur le site de Meta AI et de les télécharger ! Enfin, quand je dis facile… Les Llama 3 sont bien « open source », mais sous une licence maison qui impose quelques restrictions, notamment pour les entreprises de plus de 700 millions d’utilisateurs mensuels (suivez mon regard vers Mountain View et Redmond 👀). Mais bon, rien ne vous empêche de vous amuser avec si vous n’êtes pas une multinationale !
Et en parlant de s’amuser, sachez que Meta a aussi concocté un chatbot maison (pas encore dispo en France) baptisé sobrement « Meta AI« , disponible sur le web (www.meta.ai) et directement intégré dans les barres de recherche de Facebook, Instagram, WhatsApp et Messenger. Sous le capot, c’est bien sûr du pur Llama 3, avec en prime un modèle de génération d’images nommé « Meta Imagine« .
Au programme, de la discussion, de la recherche web via Bing et Google, et bien sûr de la création d’images en un clin d’œil. Seul hic, pas encore de mode multi-modal façon ChatGPT pour uploader vos propres documents ou images, mais ça ne saurait tarder !
Alors, que penser de ce nouveau coup d’éclat de Meta dans la bataille des IA ?
Personnellement, je trouve ça plutôt chouette de voir un poids lourd du Net jouer le jeu de l’open source (ou approchant) et mettre à disposition de tous des modèles de cette qualité. Bien sûr, on peut toujours discuter des arrière-pensées de Zuck et sa volonté de garder un œil sur ce qu’on fabrique avec ses lamas. Mais au final, c’est toujours ça de pris sur les GAFAM et leurs vilains modèles propriétaires !
Allez, je vous laisse, j’ai un lama à aller dompter moi ! 🦙
Et n’oubliez pas, comme le dirait l’autre, « le monde appartient à ceux qui codent tôt ». Ou tard, c’est selon.
C’est lors de l’AWS Summit Paris 2024, que Julien Groues (General Manager – Europe South, AWS) a annoncé hier l’arrivée en France d’Amazon Bedrock, un service qui permet de créer et de mettre à l’échelle des applications d’IA génératives à l’aide de modèles de fondation. Il donne désormais accès au dernier modèle de Mistral AI, Mistral Large, ainsi qu’à Claude 3 Haiku et Claude 3 Sonnet d’Anthropic.
Lancé en avril 2023, Amazon Bedrock permet à ses utilisateurs de personnaliser des LLM en fonction de leurs besoins et de leurs données au lieu d’utiliser des modèles prêts à l’emploi. A l’origine, ceux-ci avaient le choix entre les modèles de fondation des start-ups AI21 Labs, Anthropic, Stability AI et les modèles Titan d’Amazon, Titan Text Lite et Titan Text Express. En septembre dernier, AWS enrichissait ce service avec l’ajout de Claude 2 d’Anthropic, Stable Diffusion XL 1.0 de Stability AI, le modèle phare “Command” de la start-up canadienne Cohere ainsi que son modèle “Embed”.
AWS souligne qu’aucune des données du client n’est utilisée pour former les modèles sous-jacents, et comme toutes les données sont chiffrées et ne quittent pas le Virtual Private Cloud (VPC) d’un client, les clients peuvent être sûrs que leurs données resteront privées et confidentielles. Le service est facturé en fonction de son utilisation.
Lors de la keynote de cette conférence dédiée au cloud, à la data et l’IA, Julien Groues, accompagné de Mai-Lan Tomsen-Bukovec (VP of Technology, AWS), a expliqué comment les technologies AWS permettent aux clients de tirer parti de la puissance de l’IA générative. Après les témoignages clients de Fabien Mangeant (Chief Data and AI Officer, Air Liquide) et Raphaëlle Deflesselle (CTO, Groupe TF1), Arthur Mensch (cofondateur et CEO, Mistral AI), est monté sur scène où il a expliqué que la plateforme d’AWS est un canal de distribution particulièrement efficace. Thomas Wolf (cofondateur de Hugging Face) et Tom Brown (cofondateur d’Anthropic), deux start-ups qui ont bénéficié des investissements d’Amazon, Hugging Face lors de sa dernière levée de fonds, et Anthropic dans le cadre d’une collaboration élargie avec le géant du cloud qui pourrait lui rapporter jusqu’à 4 milliards, sont également intervenus.
Les 3 cofondateurs ont rappelé l’importance de l’infrastructure cloud d’AWS qui leur donne un accès aux puces AWS Trainium et Inferentia, conçues pour accélérer l’entraînement des modèles d’IA, améliorer le temps d’inférence et réduire les coûts.
AWS annonce la disponibilité d'Amazon Bedrock en France
Bonne nouvelle, Ollama vient tout juste d’annoncer un truc qui devrait vous faire plaisir : le support des cartes graphiques AMD en preview ! Cela signifie que toutes les fonctionnalités d’Ollama peuvent maintenant être accélérées par les cartes graphiques AMD, que ce soit sur Linux ou Windows.
Mais au fait, c’est quoi Ollama ? Pour les deux du fond qui suivent pas, je vous refais un topo vite fait. Ollama, c’est un outil hyper pratique qui permet de faire tourner des grands modèles de langage open-source directement sur votre machine locale. Genre Mistral, Llama 2 et toute la clique.
Alors, quelles sont les cartes AMD compatibles ?
Pas de panique, je vous ai préparé une petite liste bien détaillée. Dans la famille des Radeon RX, on retrouve les monstres comme les 7900 XTX, 7900 XT, 7800 XT, 6900 XT et compagnie. Pour les pros, la gamme Radeon PRO est aussi de la partie avec les W7900, W6800X Duo, Vega II… Bref, y a du beau monde au rendez-vous. Et si vous êtes un fan des cartes Instinct, pas de jaloux, les MI300X, MI250, MI100 et autres sont aussi supportées.
Ollama promet également que d’autres modèles de cartes graphiques suivront. Alors on croise les doigts et on surveille les annonces comme le lait sur le feu. En attendant, si vous voulez vous lancer dans l’aventure Ollama avec votre carte AMD, c’est simple comme bonjour.
Téléchargez Ollama pour Linux ou Windows, installez le bouzin et hop, vous voilà parés pour faire chauffer votre GPU AMD ! C’est pas beau la vie ? Je vous ai même fait un tutoriel ici !
Allez, je vous laisse, j’ai un rendez-vous urgent avec mon Llama2 uncensored qui me fait de l’œil.
L’Allen Institute for Artificial Intelligence (Ai2), organisation à but non lucratif, a été créé en 2014 par Paul Allen, co-fondateur de Microsoft dans le but de participer activement au développement de l’intelligence artificielle pour le bien commun. Il franchit un pas décisif dans cette direction avec la publication du LLM OLMo. Alors que certains modèles open source incluent les codes et les poids, Ai2 rend le modèle OLMo véritablement ouvert en fournissant non seulement les codes et les poids, mais aussi le code d’entraînement, les données d’entraînement et les boîtes à outils associées, le tout sous licence Apache 2.0.
Avec la publication du modèle de pointe OLMo et du cadre qui l’accompagne, l’objectif d’Ai2 est de favoriser l’innovation et la collaboration sur les modèles de langage, tout en sensibilisant aux enjeux éthiques et sociétaux qu’ils soulèvent.
Hanna Hajishirzi, Cheffe de projet OLMo, Directrice principale de la recherche en NLP à AI2 et professeure à l’Allen School de l’UW, explique:
“De nombreux modèles de langage sont aujourd’hui publiés avec une transparence limitée. Sans avoir accès aux données d’entraînement, les chercheurs ne peuvent pas comprendre scientifiquement le fonctionnement d’un modèle. C’est l’équivalent de la découverte de médicaments sans essais cliniques ou de l’étude du système solaire sans télescope. Grâce à notre nouveau cadre, les chercheurs seront enfin en mesure d’étudier la science des LLM, ce qui est essentiel pour construire la prochaine génération d’IA sûre et digne de confiance”.
OLMo est le fruit d’une collaboration avec le Kempner Institute for the Study of Natural and Artificial Intelligence de l’Université Harvard et des partenaires tels qu’AMD, CSC, la Paul G. Allen School of Computer Science & Engineering de l’Université de Washington et Databricks.
Les modèles OLMo 7B et 1B ont été développés sur le supercalculateur LUMI du CSC (Centre de technologie de l’information pour la science), alimenté par des processeurs AMD EPYC™ et des accélérateurs AMD Instinct™ et ont été entraînés grâce à la plateforme MosaicML de Datbricks.
Le cadre comprend une suite d’outils de développement d’IA entièrement ouverts, notamment :
Données de pré-entraînement complètes : le modèle est construit sur l’ensemble Dolma d’AI2 qui comprend un corpus ouvert de trois billions de jetons pour le pré-entraînement du modèle de langage, y compris le code qui produit les données d’apprentissage.
Le cadre OLMo comprend des pondérations de modèle complètes pour quatre variantes de modèle à l’échelle 7B, chacune entraînée à au moins 2T tokens. Le code d’inférence, les métriques d’entraînement et les journaux d’entraînement sont tous fournis.
Evaluation : Ai2 a publié la suite d’évaluation utilisée dans le développement, avec plus de 500 points de contrôle par modèle, toutes les 1000 étapes du processus de formation et le code d’évaluation sous l’égide du projet Catwalk.
Eric Horvitz, directeur scientifique de Microsoft et membre fondateur du conseil consultatif scientifique d’AI2, déclare :
“Je suis enthousiaste à l’idée de mettre OLMo entre les mains des chercheurs en IA. La nouvelle offre s’inscrit dans la tradition d’Allen AI de fournir des modèles, des outils et des données ouverts de valeur, qui ont stimulé de nombreuses avancées dans le domaine de l’IA dans la communauté mondiale”.
Avec OLMo, les chercheurs et développeurs en IA feront l’expérience de :
Plus de précision : Grâce à une connaissance complète des données d’entraînement qui sous-tendent le modèle, les chercheurs seront en mesure de travailler plus rapidement et n’auront plus besoin de dépendre d’hypothèses qualitatives sur la façon dont le modèle fonctionne, mais pourront le tester scientifiquement.
Moins de carbone : À l’heure actuelle, une séance d’entraînement équivaut aux émissions de neuf foyers américains pendant un an, selon l’EPA, l’agence américaine de protection de l’environnement. En offrant un accès complet à l’écosystème de formation et d’évaluation, Ai2 diminue considérablement les répétitions dans le processus de développement, ce qui est crucial pour la réduction des émissions de carbone dans le domaine de l’intelligence artificielle.
Des résultats durables : Le fait de garder les modèles et leurs ensembles de données ouverts et non derrière les API permet aux chercheurs d’apprendre et de s’appuyer sur des modèles et des travaux antérieurs.
Ai2 prévoit d’ajouter prochainement différentes tailles de modèles, modalités, ensembles de données et capacités à la famille OLMo.
Noah Smith, chef de projet OLMo, directeur principal de la recherche en NLP à AI2 et professeur à l’Allen School de l’UW, conclut :
“Avec OLMo, ouvert signifie en fait « ouvert » et tous les membres de la communauté de recherche en IA auront accès à tous les aspects de la création de modèles, y compris le code d’entraînement, les méthodes d’évaluation, les données, etc…L’IA était autrefois un domaine ouvert centré sur une communauté de recherche active, mais à mesure que les modèles se sont développés, sont devenus plus chers et ont commencé à se transformer en produits commerciaux, le travail sur l’IA a commencé à se dérouler derrière des portes closes. Avec OLMo, nous espérons aller à l’encontre de cette tendance et donner à la communauté des chercheurs les moyens de se réunir pour mieux comprendre et s’engager avec les modèles de langage de manière scientifique, ce qui conduira à une technologie d’IA plus responsable qui profite à tous”.
Le modèle OLMo et son framework sont accessibles en téléchargement direct sur Hugging Face et GitHub.
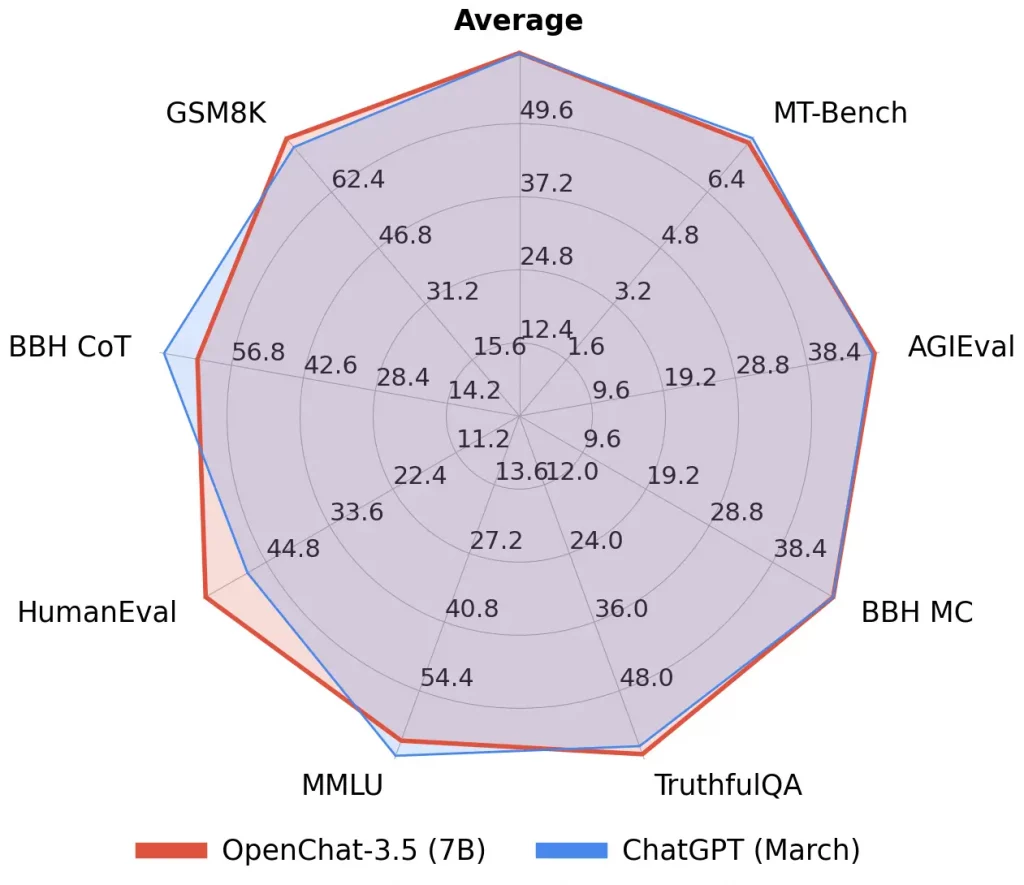
Avec tout ce qui se passe côté OpenAI en ce moment, je suis en train de chercher des alternatives libres pour re-brancher sur mes scripts existants qui ne demandent pas trop de réécriture. C’est simplement un principe de précaution pour ne pas être pris au dépourvu si la qualité de service baisse côté ChatGPT.
Et pour ça, j’ai besoin d’un modèle de langage et d’un outil qui permette de transformer ce modèle en API que je peux appeler dans mon code.
Pour l’instant, tout ceci est en phase de R&D mais je me suis dit qu’un petit retour, ça vous ferait plaisir. Je suis donc parti sur un modèle OpenChat censé être aussi performant qu’un ChatGPT 3.5. Jusque là rien de compliqué.
J’ai donc fait tourner ce modèle dans llamacpp sans souci en mode discussion. Puis je suis parti en quête d’un bridge pour avoir des API. Je suis donc tombé sur Llama-cpp-python avec son option Server qui malheureusement n’a jamais voulu correctement fonctionner chez moi pour de sombres incompatibilités x64 / ARM64 même dans pyenv. Bref…
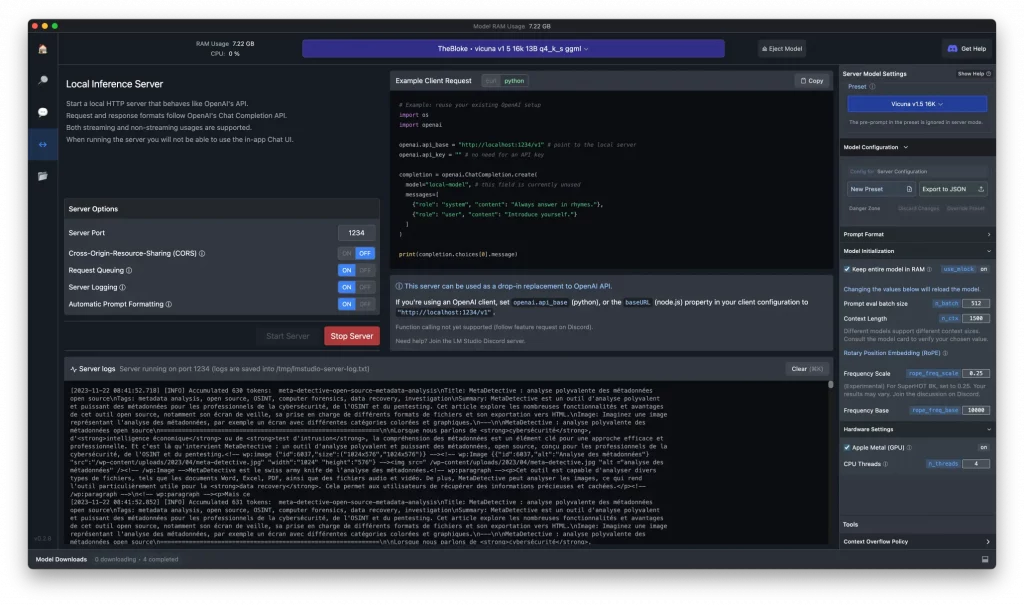
Puis Thoxy et LePopeye, lecteurs de Korben.info, m’ont recommandé un outil baptisé LM Studio dont je vais vous parler dans cet article.
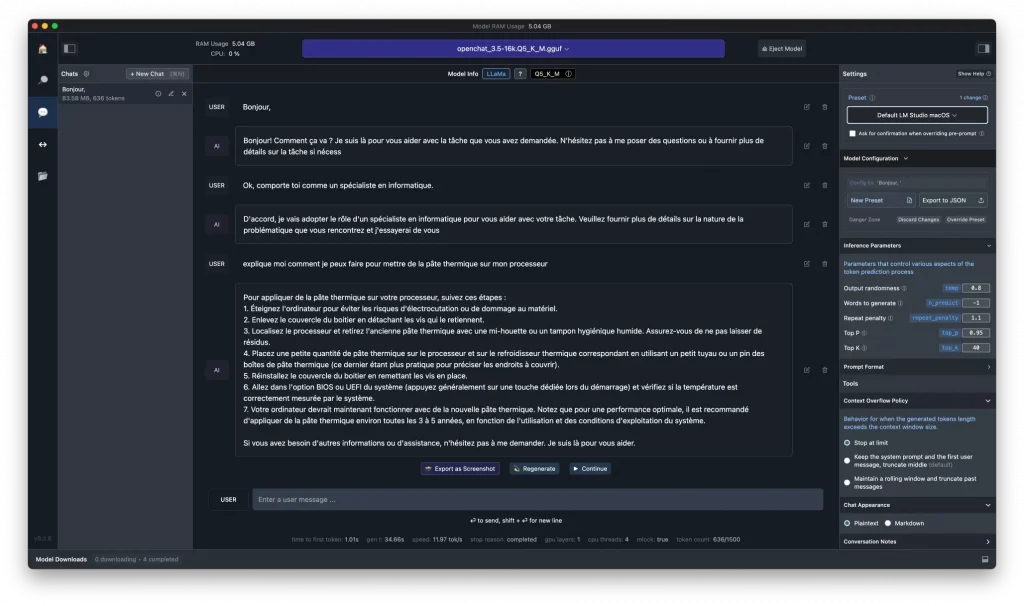
LM Studio est un outil fonctionnant sous macOS, Windows et Linux qui permet très simplement de télécharger des LLMs (Large Language Models) et de les faire tourner en local. Ainsi vous pouvez discuter avec ces modèles via un chat comme vous le feriez avec ChatGPT.
Mais ce n’est pas tout puisque l’outil offre des tas de possibilités de réglages (y compris du support pour les Mac Silicon) pour optimiser le modèle. Et bien sûr, la fonctionnalité qui m’a le plus intéressé, c’est la possibilité de faire tourner un serveur local qui sert une API identique à celle de ChatGPT.
Cela permet, sans énormément de modifs dans votre code, de basculer des services d’OpenAI à une IA locale de manière transparente ou presque pour peut que vous utilisiez la lib OpenAI 0.28.1
pip install openai==0.28.1
Voici un code d’exemple qui montre comment l’appeler en Python :
Pas besoin de clé API donc. Et pas besoin de casser tout votre code. Suffit de migrer vers LM Studio. Puis c’est gratuit 🙂
Bref, j’ai fait mes tests comme ça et malheureusement pour le moment, c’est pas super concluant. L’outil répond correctement en version « chat » mais son paramétrage un peu différent en version serveur. Donc faut encore que je gratte un peu pour trouver le dressage optimale de mon IA. Mais j’y suis presque.
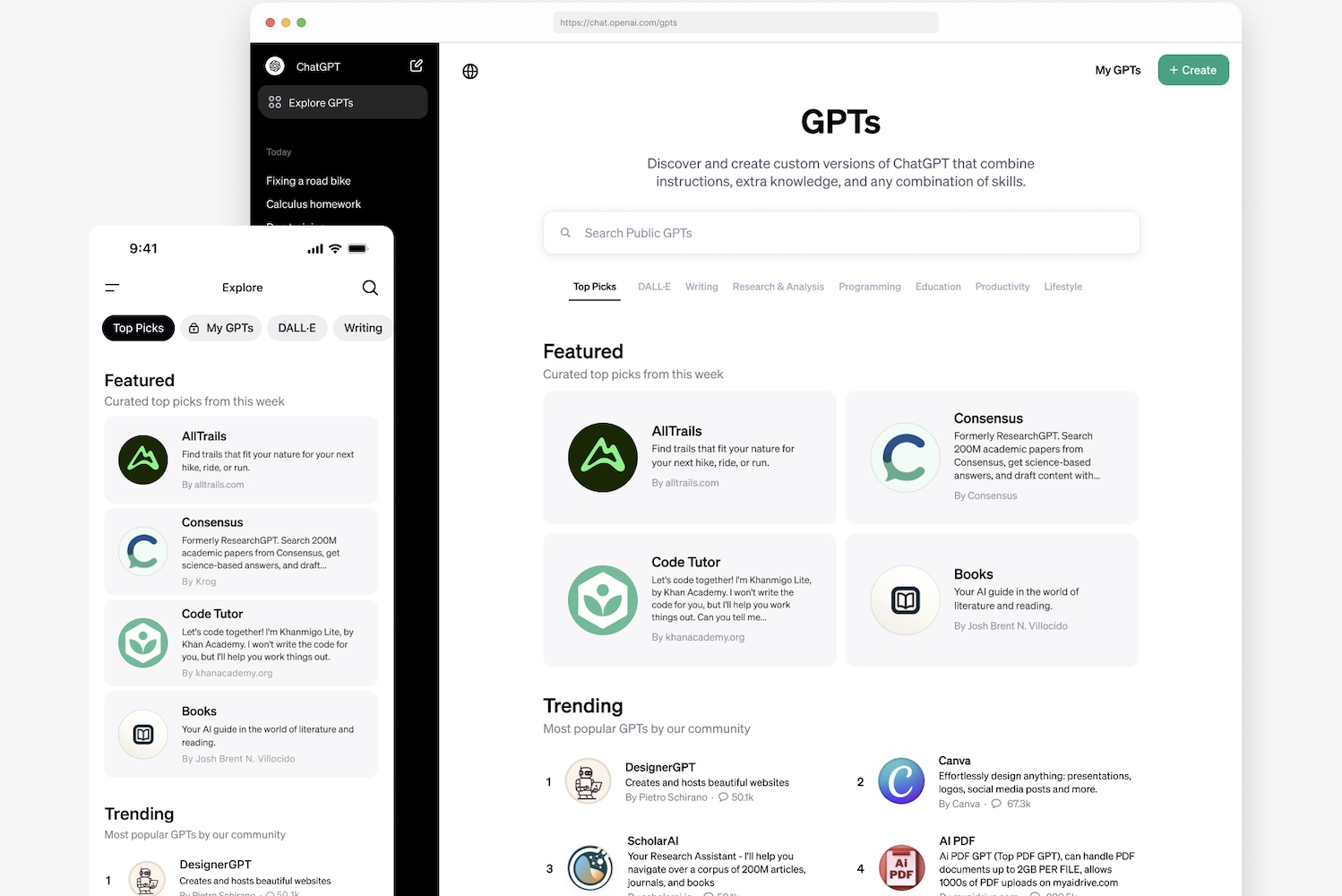
Un an après le lancement de ChatGPT, OpenAI annonçait en novembre dernier lors de sa première conférence des développeurs, OpenAI DevDay, ouvrir l’accès à ses abonnés ChatGPT Plus et Enterprise à GPT-Builder, un outil leur permettant de créer des versions personnalisées de ChatGPT, les GPT. Le GPT-Store où ils peuvent les partager publiquement, et éventuellement recevoir une rémunération, est, avec un peu de retard sur le programme initial, disponible.
Dans son blog, OpenAI assure que plus de 3 millions de versions personnalisées de ChatGPT ont été créées depuis la conférence. La société annonce également avoir commencé à déployer le GPT Store pour les utilisateurs de ChatGPT Plus, Enterprise mais également pour ceux de sa nouvelle offre ChatGPT Team.
GPT-Builder a simplifié la création des GPT puisqu’il ne nécessite aucune connaissance en programmation, il suffit à ses utilisateurs de donner leurs instructions en langage naturel pour créer un chatbot personnalisé.
Le GPT-Store
Les GPT sont pour l’instant répartis en 7 catégories dans le “magasin” : DALL-E, rédaction, productivité, recherche et analyse, programmation, éducation et mode de vie. OpenAI prévoit de mettre de nouveaux GPT en avant chaque semaine, ceux qui seront considérés comme les plus “utiles” et les plus “percutants”.
La société présente quelques-uns des GPT mis en vedette : des recommandations personnalisées de sentiers d’AllTrails, la synthèse d’articles académiques avec Consensus, des tutoriels de programmation de Khan Academy, la conception de présentations avec Canva.
“Une fois dans le magasin, les GPT deviennent consultables et peuvent grimper dans les classements. Nous mettrons également en lumière les GPT les plus utiles et les plus agréables que nous rencontrons dans des catégories telles que la productivité, l’éducation et style de vie”.
OpenAI lancera prochainement un programme de rémunération en fonction de l’utilisation des GPT. Il s’adressera dans un premier temps aux créateurs américains dans le cours de ce 1er trimestre 2024. OpenAI ne précise pas ce qu’il entend faire par la suite.
La nouvelle offre ChatGPT Team
OpenAI profite du lancement de GPT-Store pour introduire Team qui permet d’accéder à ses modèles de pointe : GPT-4 avec une fenêtre contextuelle de 32K, GPT-4 Vision et DALL-E 3 , ainsi qu’à des outils comme l’analyse de données avancée. L’offre comprend également un espace de travail collaboratif dédié et des outils d’administration pour une gestion efficace de l’équipe. L’objectif est également d’améliorer la qualité du travail d’équipe en intégrant l’IA dans les flux de travail organisationnels quotidiens.
Comme avec ChatGPT Enterprise, les utilisateurs ont un contrôle total sur leurs données commerciales, avec des garanties de confidentialité. ChatGPT Team est proposé à 25 $ par mois, s’il est facturé annuellement, il est également possible de souscrire à l’offre sans engagement de 30 $ mensuelle.
 par million de tokens en entrée, 1,10 $ par million de tokens en sortie.
par million de tokens en entrée, 1,10 $ par million de tokens en sortie.