Sommaire
Près de 350 tickets ont été clos dans le cadre du travail sur la version R1 bêta 5. Il y a bien sûr de très nombreuses corrections de bugs, qui ne seront pas listées dans cet article. On se concentrera plutôt sur les nouveautés, sauf dans les cas où la correction est vraiment importante ou permet d’ouvrir de nouvelles possibilités d’utilisation.
Applications
Haiku est un système d’exploitation complet, fourni avec un certain nombre d’applications permettant d’accomplir les tâches les plus courantes. En plus de ces applications de base, le gestionnaire de paquets HaikuDepot, alimenté principalement par le travail du projet HaikuPorts, apporte à la fois des applications portées depuis d’autres systèmes et des applications développées spécifiquement pour Haiku.
De façon générale, on trouve cette année dans les applications de Haiku des améliorations sur le rendu des nombres, l’utilisation d’un symbole de multiplication à la place d’une lettre x là où c’est pertinent, et de nombreuses petites corrections et améliorations sur la mise en page des fenêtres, des corrections de problèmes de traduction et ainsi de suite.
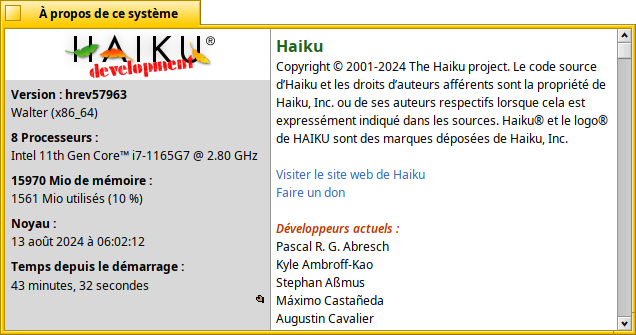
AboutSystem
AboutSystem est la fenêtre d’information sur le système Haiku. Elle fournit quelques informations sur la machine sur laquelle le système fonctionne (quantité de RAM, marque et modèle du CPU, uptime) ainsi que les noms des développeurs et autres logiciels libres ayant participé au développement de Haiku.
Cette application reçoit tout d’abord une mise à jour cosmétique : si le système est configuré en « mode sombre », le logo Haiku correspondant (avec un lettrage blanc et des dégradés de couleurs un peu différents) sera utilisé. Sinon, ce sera le logo avec lettrage noir.

Elle reçoit également quelques mises à jour de contenu : en plus de l’ajout de quelques nouveaux contributeurs qui ont rejoint le projet, on trouvera maintenant un lien vers la page web permettant de faire un don à Haiku. Plusieurs liens vers des bibliothèques tierces utilisées dans Haiku, qui ne fonctionnaient plus, ont été soit supprimés, soit remplacés par des liens mis à jour.
Enfin, il est désormais possible d’utiliser AboutSystem comme un « réplicant », c’est-à-dire de l’installer directement sur le bureau pour avoir en permanence sous les yeux les statistiques sur l’utilisation mémoire et l’uptime ainsi que le numéro de build de Haiku en cours d’exécution (ce qui peut être utile par exemple lorsqu’on lance beaucoup de machines virtuelles avec des versions différentes de Haiku pour comparer un comportement, ou si on veut stocker des captures d’écran de plusieurs versions et s’y retrouver facilement).
CharacterMap
L’application « table de caractères » permet d’étudier de près les différents glyphes et symboles présents dans une police de caractères. En principe, elle permet de choisir une police spécifique, mais le serveur graphique de Haiku substitue automatiquement une autre police si on lui demande d’afficher un caractère qui n’est pas disponible dans la police demandée.
Cela peut être gênant dans certains contextes, par exemple si on envisage d’embarquer une police dans un fichier PDF, il est difficile de savoir quelle police contient vraiment les caractères qu’on veut utiliser.
L’application a été améliorée pour traiter ce cas et affiche maintenant ces caractères en grisé.
CodyCam
CodyCam est une application permettant de tester une webcam et de l’utiliser pour envoyer périodiquement des images vers un serveur HTTP.
L’évolution principale a été la mise à jour de l’icône de l’application. L’utilité de CodyCam est limitée par le manque de pilotes : il faudra soit trouver une webcam Sonix du début des années 90, seul modèle USB à disposer d’un pilote fonctionnel, soit utiliser un ordiphone Android équipé d’un logiciel permettant de le transformer en caméra IP (ou encore une vraie caméra IP).
Le pilote pour les WebCams UVC — standard utilisé pour les caméras USB modernes — n’est pas encore au point et n’est pas inclus dans les versions publiées de Haiku.
Debugger
Debugger est, comme son nom l’indique, le debugger de Haiku. Il est développé spécifiquement pour le projet sans s’appuyer sur les outils existants (gdb ou lldb). Il dispose à la fois d’une interface graphique et d’une interface en ligne de commande, plus limitée. Cette dernière est surtout utilisée pour investiguer des problèmes dans les composants de Haiku qui sont nécessaires pour l’utilisation d’une application graphique : app_server, input_server ou encore registrar.
La version en ligne de commande a reçu quelques petites améliorations, mais la principale nouveauté est la prise en charge des formats DWARF-4 et DWARF-5 pour les informations de debug. Cela permet de charger les informations générées par les versions modernes de GCC, sans avoir besoin de forcer la génération d’une version plus ancienne du format DWARF.
Le désassembleur udis86, qui n’est plus maintenu et ne reconnaît pas certaines instructions ajoutées récemment dans les processeurs x86, a été remplacé par Zydis.
Enfin, un bug assez gênant a été corrigé : si une instance de Debugger était déjà en train de débugger une application et qu’une deuxième application venait à planter, il n’était pas possible d’attacher une deuxième instance de Debugger à cette application. Les problèmes impliquant plusieurs processus pouvaient donc être un peu compliqués à investiguer. C’est maintenant résolu.
Deskbar
L’application DeskBar fournit la « barre des tâches » de Haiku. Elle permet de naviguer entre les fenêtres et applications ouvertes, de lancer de nouvelles applications via un menu (similaire au « menu démarrer » de Windows), ou encore d’afficher une horloge et des icônes fournis par d’autres applications (sous forme de réplicants).
Elle fait partie, avec le Tracker, des applications qui ont été publiées sous license libre lors de l’abandon de BeOS par Be Inc.
Quelques changements dans la DeskBar :
- Tous les menus utilisent maintenant la police « menu » choisie dans les préférences d’apparence du système. Auparavant, la police « menu » et la police « plain » étaient mélangées. Ces deux polices étant identiques dans la configuration par défaut, le problème n’avait pas été repéré.
- Si un nom de fenêtre est tronqué dans la liste des fenêtres, le nom complet peut être affiché dans une infobulle.
- L’icône pour les fenêtres dans la DeskBar a été remplacée. La nouvelle icône indique plus clairement si une fenêtre se trouve dans un autre bureau virtuel (dans ce cas, activer cette fenêtre provoquera un changement de bureau).
GLTeapot
GLTeapot est une application permettant de tester le rendu OpenGL, en affichant un modèle 3D de la théière de l’Utah.
En plus de la théière, cette application affiche un compteur du nombre d’images affichées par secondes. Bien que les chiffres affichés ne soient pas du tout représentatifs des performances d’un rendu 3D réaliste, certains utilisateurs insistent lourdement pour pouvoir faire le concours de gros chiffres de nombre d’images par seconde.
Il est donc à nouveau possible de désactiver la synchronisation sur le rafraîchissement de l’écran, et demander au processeur de réafficher la théière plusieurs centaines de fois par seconde, bien que l’écran soit incapable de suivre le rythme. Par défaut, la synchronisation est activée et le rafraîchissement ne dépassera jamais 60 FPS, si toutefois le pilote graphique implémente les fonctions de synchronisation nécessaires.
HaikuDepot
HaikuDepot est un hybride entre un gestionnaire de paquets et un magasin d’applications.
Il se compose d’un serveur (développé en Java) fournissant une API REST et permettant de collecter les informations sur les applications (icônes, captures d’écrans, catégories, votes et revues des utilisateurs, choix de la rédaction pour les applications mises en avant…), d’un frontend web minimaliste et d’une application native C++ permettant d’afficher ces données.
La principale nouveauté est l’intégration du système de single-sign-on (SSO) permettant d’utiliser un compte utilisateur commun avec d’autres services en ligne de Haiku. Actuellement, l’outil de revue de code Gerrit
utilise ce même compte, mais ce n’est pas encore le cas pour Trac (outil de suivi des bugs) ni pour le forum. Ce sera mis en place plus tard.
De façon peut-être moins visible, mais pas moins importante, le code C++ de l’application a reçu de nombreuses améliorations et optimisations « sous le capot », rendant l’application plus rapide et plus fiable, mais qui sont un peu difficiles à résumer dans le cadre de cette dépêche.
Enfin, l’apparence de l’application a été légèrement retravaillée pour mieux s’adapter aux écrans à haute définition (ce qui nécessite d’avoir des marges et espacements de taille dynamique en fonction de la taille de texte choisie par l’utilisateur).
Icon-O-Matic
Icon-O-Matic est un éditeur d’icônes. Il permet d’exporter les fichiers au format HVIF, un format vectoriel compact qui permet de stocker les icônes dans l’inode d’en-tête des fichiers pour un chargement et un affichage rapide.
Cette application a bénéficié du travail de Zardshard pendant le Google Summer of Code 2023, elle a donc reçu plusieurs évolutions et corrections importantes (dont certaines sont mentionnées dans la dépêche anniversaire de l’année dernière).
Citons en particulier l’ajout d’un nouveau type de transformation, « perspective », qui permet de facilement déformer un ensemble de chemins vectoriels selon une projection de perspective, ce qui est assez utile pour concevoir plus facilement une icône avec un aspect tridimensionnel (bien qu’en pratique l’apparence habituelle des icônes de Haiku soit un intermédiaire entre une projection perspective et une vue isométrique, ne se prêtant pas forcément à l’utilisation de cette opération de transformation purement mathématique).
Une autre petite amélioration est l’ajout d’une vérification pour empêcher la fenêtre de Icon-O-Matic de se positionner en dehors de l’écran, par exemple si on a déplacé la fenêtre vers le bas de l’écran, enregistré cette position, puis relancé l’application dans une résolution d’écran plus réduite. Dans ce cas, la fenêtre sera automatiquement ramenée dans la zone visible de l’affichage.
Magnify
L’application Magnify permet d’afficher une vue zoomée d’une partie de l’écran. Elle peut servir pour améliorer l’accessibilité (mais n’est pas idéale pour cet usage), mais aussi pour les développeurs d’interfaces graphiques qui ont parfois besoin de compter les pixels pour s’assurer que leurs fenêtres sont bien construites.
En plus de l’affichage zoomé, l’application permet d’afficher l’encodage RGB de la couleur d’un pixel, ou encore de placer des « règles » permettant de vérifier l’alignement des objets. Ces dernières ont reçu une petite mise à jour, avec une amélioration de l’affichage de leur largeur et hauteur pour les rendre plus lisibles.
MediaPlayer
L’affichage des sous-titres ne fonctionnait pas correctement, il manquait une partie du texte. C’est maintenant corrigé.
PowerStatus
L’application PowerStatus permet de surveiller l’état de la batterie pour les ordinateurs qui en disposent.
Elle a reçu plusieurs améliorations importantes :
Une notification a été ajoutée pour un niveau de décharge très faible (en plus du niveau faible déjà présent). Ces deux niveaux peuvent être paramétrés à un pourcentage choisi de décharge de la batterie, et associé à des sons d’alerte spécifiques. Avant ces changements, il était facile de ne pas voir le message d’alerte (affiché seulement pendant quelques secondes) ou de se dire qu’avec 15% de batterie on a encore le temps de faire plein de trucs, puis se retrouver un peu plus tard avec une batterie vide sans autre avertissement.
L’état « not charging » est maintenant détecté et correctement affiché, pour une batterie au repos : ni en train de se charger, ni en train d’alimenter la machine. C’est en particulier le cas d’une batterie déjà chargée à 100%, si la machine reste connectée au réseau électrique.
L’icône de statut de la batterie s’installe automatiquement dans la DeskBar au premier démarrage de Haiku sur les machines disposant d’une batterie.
Le réglage du mode « performance » ou « économie d’énergie" est enregistré et ré-appliqué lors des prochains démarrages (ces modes configurent l’ordonnanceur du noyau pour exécuter un maximum de tâches sur tous les cœurs du processeur, ou bien au contraire pour essayer de garder ces cœurs en veille autant que possible s’ils ne sont pas nécessaires).
SerialConnect
SerialConnect est une application de terminal série, utile principalement aux développeurs de systèmes embarqués et autres gadgets électroniques.
Elle est encore en cours de développement et propose pour l’instant les fonctions les plus basiques. Il est maintenant possible de coller du texte depuis le presse-papier pour l’envoyer sur un port série, ce qui est pratique si on veut envoyer plusieurs fois la même séquence de commandes.
ShowImage
ShowImage est la visionneuse d’images de Haiku. Elle utilise les traducteurs, des greffons avec une API standardisée qui permettent de convertir différents formats de fichiers entre eux.
L’interface graphique de ShowImage a été mise à jour pour utiliser le « layout system ». Historiquement, dans BeOS, tous les éléments des interfaces graphiques devaient être positionnés manuellement avec des coordonnées en pixels, ce qui est pénible à faire, surtout si on doit traiter tous les cas (polices de caractères de différentes tailles, remplacement des textes lors de traductions, utilisation de thème d’interfaces différents), et aussi lors d’évolution de l’application (si on veut insérer un élément en plein milieu, il faut souvent décaler tout ce qui se trouve autour).
Le « layout system » fournit un ensemble d’outils pour automatiser ce travail, soit à l’aide d’éléments prédéfinis (grilles, groupes, « cartes » superposées), soit à l’aide d’un système de définition de contraintes et de programmation linéaire.
D’autre part, ShowImage dispose maintenant d’un menu permettant d’ouvrir l’image affichée dans un éditeur d’images.
Terminal
Le Terminal de Haiku permet d’exécuter un shell (c’est bash par défaut) et toutes les applications conçues pour un affichage en console.
Les principaux changements cette année sont la correction d’un problème sur la configuration des couleurs utilisées par le Terminal (il y avait un mélange entre le nom anglais et le nom traduit des couleurs, empêchant d’enregistrer et de relire correctement le fichier de configuration), ainsi que des modifications sur les raccourcis clavier utilisés par le Terminal lui-même (en particulier pour naviguer entre plusieurs onglets) qui entraient en conflit avec ceux utilisés par les applications lancées dans le terminal.
Le terminal est également capable de traiter les « bracketed paste », c’est-à-dire que les applications en console sont informées que des caractères en entrée proviennent du presse-papier. Cela permet par exemple à bash de ne pas exécuter directement des commandes qui sont collées, mais de les mettre en surbrillance et d’attendre que l’utilisateur valide cette saisie.
D’un point de vue plus bas niveau, les pilotes TTY utilisés pour les ports série et pour le Terminal, qui étaient indépendants, ont été unifiés afin d’éviter de devoir corriger tous les bugs deux fois dans deux versions du code presque identiques.
Tracker
Tracker est le navigateur de fichiers de Haiku. Tout comme la DeskBar, il fait partie des quelques rares morceaux de BeOS qui ont été publiés sous licence libre par Be et ont donc pu être repris directement par Haiku. Contrairement à la DeskBar, la publication du code du Tracker avait conduit à l’apparition de nombreux forks, chacun améliorant à sa façon le logiciel. La version utilisée par Haiku provient principalement du projet OpenTracker, mais a réintégré ou réimplémenté au fil du temps les modifications faites dans d’autres variantes.
Le Tracker est un composant central de l’interface de Haiku et a donc reçu un nombre assez important d’évolutions :
La taille des fichiers est maintenant affichée à l’aide de la fonction string_for_size qui s’adapte aux conventions de la langue et du pays choisi par l’utilisateur.
Les brouillons de courrier électronique disposent maintenant de leur propre type MIME et de l’icône associée. Ils s’ouvriront dans un éditeur de mail plutôt que dans une fenêtre de lecture de message.
Pour les fichiers qui disposent d’un attribut « rating » (évaluation), ce dernier est affiché avec des étoiles pleines ou vides selon la note attribuée. La note va de 0 à 10 mais il n’y a que 5 étoiles. Le caractère demi-étoile permet d’afficher la note exacte avec les versions récentes d’Unicode (depuis 2018 en fait, mais il a fallu attendre la disponibilité dans une police de caractères).
La gestion des dossiers en lecture seule a été améliorée. Ils sont affichés sur fond gris (au lieu d’un fond blanc pour les dossiers modifiables) et tous les menus correspondant à des opérations non autorisées sont désactivés (au lieu d’être activés, mais d’aboutir sur une erreur car le dossier est en lecture seule).
Dans le même esprit, le bouton « ouvrir » des boîtes de dialogues d’ouverture de fichier est désactivé si le fichier sélectionné ne peut pas être ouvert (c’était déjà le cas, mais tous les cas possibles n’étaient pas bien pris en compte).
Un problème d’affichage sur le système de fichier packagefs a été corrigé : les dossiers n’ont pas de taille et affichent donc - au lieu d’une taille fixe de 4 Kio qui n’a aucune signification.
La fenêtre de recherche a reçu quelques évolutions, voir plus bas dans la section dédiée au Google Summer of Code, qui détaille le travail réalisé à ce sujet.
Le menu « templates », utilisé quand on fait un 'clic droit -> Nouveau…' et qui permet de créer différents types de fichiers et de dossiers à partir de fichiers de référence, peut maintenant contenir des sous-dossiers, pour les personnes qui utilisent beaucoup cette possibilité, avec par exemple des modèles de documents pré-remplis pour différents usages.
Enfin, un peu de nettoyage interne : les classes NavMenu et SlowContextPopup, qui permettent la navigation dans les sous-dossiers via des menus popup, ont été fusionnées en une seule classe car elles sont toujours utilisées ensemble. Cela simplifie le code pour l’affichage de ces menus, qui a quelques particularités pour permettre une navigation confortable même sur un disque dur un peu lent.
TV
L’application TV utilisée pour recevoir la TNT à l’aide d’un tuner approprié a été déplacée dans le paquet haiku_extras et n’est donc plus installée par défaut. La plupart des gens ne disposant pas d’un tuner compatible sur leur ordinateur, cette application était source de confusion et de nombreuses questions sur le forum.
WebPositive
WebPositive est le navigateur web de Haiku. Il utilise le moteur WebKit développé conjointement par Apple, Igalia et Sony principalement.
En dehors de la mise à jour du moteur vers une version plus récente, WebPositive reçoit actuellement peu d’évolutions, les développeurs étant malheureusement trop occupés par ailleurs. On peut toutefois mentionner une correction sur la barre de signets : celle-ci ne s’affichait jamais lorsque la langue du système était autre chose que l’anglais.
Zip-O-Matic
Zip-O-Matic est un outil permettant de créer une archive zip facilement depuis le Tracker. Il a reçu une amélioration qui est en fait une correction d’un problème qui existait depuis longtemps : l’archive créée est maintenant automatiquement sélectionnée dans le navigateur de fichier à la fin du processus, ce qui permet de facilement la retrouver pour la renommer, la déplacer ou l'envoyer à son destinataire.
Haikuports
Haikuports est un projet indépendant de Haiku, il se charge d’alimenter le dépôt de paquets. Au départ il s’agissait principalement d’un projet pour le portage de bibliothèque et de programmes venant d’autres systèmes (d’où son nom), mais il est également utilisé pour la plupart des applications natives développées pour Haiku.
Le dépôt de paquets contient actuellement 4193 paquets, il est mis à jour en continu par une petite équipe de bénévoles qui ne sont pas forcément tous développeurs, mais tout de même capables de faire les tâches de maintenance ainsi que le développement de quelques patchs simples.
Il est impossible de lister toutes les mises à jour et ajouts, le projet HaikuPorts étant très actif. Donc voici une sélection arbitraire de quelques nouveautés et mises à jour.
Applications natives
- Mises à jour de Renga (client XMPP), PonpokoDiff (outil de diff), 2pow (clone de 2048), StreamRadio (lecteur de podcasts), NetSurf (navigateur web léger)…
- Genio, un IDE pour Haiku avec gestion de la complétion de code via le protocole LSP (compatible avec les outils développés pour VS Code par exemple).
- Ajout de HaikuUtils, un ensemble d’outils de développement et de debug divers.
- WorkspaceNumber, un replicant pour afficher le numéro du bureau actif dans la DeskBar.
- KeyCursor, un outil pour contrôler le curseur de souris à l’aide du clavier.
- BatchRename, un outil pour renommer automatiquement des fichiers par lot.
Applications portées
- Un gros travail a été fait sur le portage de KDE Frameworks et des applications l’utilisant. De très nombreuses applications Qt et KDE sont donc disponibles.
- Du côté de GTK, il n’existait pas de version de GTK pour Haiku, le problème a été résolu à l’aide d’une couche de compatibilité avec Wayland qui n’implémente pas le protocole Wayland mais réimplémente l’API de la libwayland. Les applications GTK arrivent petit à petit, mais l’intégration est pour l’instant beaucoup moins bonne qu’avec Qt, qui dispose lui d’un vrai port utilisant les APIs natives directement. L’apparence des applications est très visiblement différente, certaines touches du clavier ne fonctionnent pas. C’est donc encore un peu expérimental.
- Enfin, pour compléter les possibilités d’outils graphiques, la bibliothèque Xlibe implémente les APIs de la libx11 (mais pas le protocole de communication de X) et permet de porter les applications FLTK par exemple, ainsi que celles utilisant directement la libx11. Il reste encore des problèmes avec les applications utilisant Tk (si vous connaissez Tk ou X, les développeurs de Xlibe aimeraient bien un petit coup de main). En attendant, les applications Tk sont utilisables à travers un portage de undroidwish, mais ça reste peu confortable.
Du côté des compilateurs et des langages de programmation : LLVM a été mis à jour en version 17. GCC est disponible en version 13 et peut maintenant être utilisé pour compiler du FORTRAN et de l’Objective-C. Les dernières versions de Python sont disponibles, et en plus avec des performances améliorées. Node.JS est également mis à jour, ou si vous préférez le langage R, vous le trouverez également, avec son IDE associé rkward.
Bien sûr, la plupart des bibliothèques et outils disponibles sur d’autres systèmes sont aussi disponibles : ffmpeg (en version 6), Git, libreoffice, Wireshark…
Mentionnons enfin un pilote FUSE pour monter des volumes réseau NFS, qui vient compléter les deux implémentations de NFS présentes dans le noyau (une obsolète qui implémente NFS2, et une plus récente implémentant NFS4, mais qui est instable et pas activement maintenue actuellement).
Panneaux de préférences
Appearance
Les préférences « Appearance » permettent de configurer l’apparence du système et des applications : principalement les polices de caractères et les choix de couleurs.
C’est ce dernier qui reçoit une mise à jour en profondeur, avec l’ajout d’un mode automatique. Auparavant, chaque couleur utilisée par le système devait être configurée manuellement, ce qui permet un contrôle très fin, mais demande de passer un certain temps à faire des ajustements. Le mode automatique permet de configurer seulement 3 couleurs : le fond des fenêtres, les barres de titres, et une couleur d’« accentuation ». Les autres couleurs et nuances sont calculées automatiquement à partir de cette palette de base.
En particulier, il devient beaucoup plus facile de choisir un fond sombre pour se retrouver avec un système en mode sombre, très à la mode chez certain·e·s utilisateurices de Haiku.
Il est toujours possible d’activer le mode avancé pour affiner les réglages si nécessaire (ou si vous aimez les interfaces graphiques bariolées et multicolores).
Keymap (disposition clavier)
L’application Keymap permet de configurer la disposition de touches du clavier. Le point qui a reçu un peu d’attention est la gestion de la configuration des touches modificatrices.
Haiku est un dérivé de BeOS qui lui-même a été au départ inspiré de Mac OS. On conserve de cet héritage l’utilisation des touches commande et option au lieu de meta et alt sur les claviers de PC. Mais BeOS et Haiku sont conçus pour être utilisés avec des claviers de PC. La touche commande qui prend la place de la touche ALT est donc celle utilisée pour la plupart des raccourcis claviers. Cela se complique si on essaie d’utiliser un clavier fabriqué par Apple (les codes de touches renvoyés par le clavier pour des touches situées au même endroit ne sont pas les mêmes), ou encore si on a besoin d’une touche AltGr (historiquement utilisée comme touche option par BeOS, mais aujourd’hui ce rôle est plutôt attribué à la touche windows apparue un peu plus tard). Une page sur le wiki de développement de Haiku tente de résumer l’historique et la situation actuelle.
La configuration des touches modificatrices est donc un sujet complexe, et il est probable que le comportement sera à nouveau modifié plus tard. Quoi qu’il en soit, en attendant, l’application Keymap permet toutes les permutations possibles de configuration de ces touches.
Screen (Affichage)
Les préférences d’affichage, en plus de permettre de changer la résolution d’écran, affichent quelques informations essentielles sur la carte graphique et l’écran en cours d’utilisation. Pour les écrans, ces informations sont généralement extraites des données EDID, mais il y a une exception : les dalles d’affichage des PC portables n’implémentent en général pas ce protocole. Les informations sont donc récupérées par d’autres moyens parfois moins bien normalisés. Par exemple, l’identifiant du fabricant est un code à 3 lettres. En principe, les fabricants doivent s’enregistrer auprès d’un organisme qui attribue ces codes, afin d’en garantir l’unicité.
Cependant, certains fabricants ne l’ont pas fait, et se sont choisi eux-mêmes un code qui semblait inutilisé. La base de données officielle réserve donc ces codes et en interdit l’utilisation, afin d’éviter des conflits. Il arrivait donc que le fabriquant d’un écran soit affiché comme étant « DO NOT USE », ce qui a inquiété quelques utilisateurs de Haiku se demandant s’ils risquaient d’endommager leur matériel.
Ces entrées de la liste sont maintenant filtrées et remplacées par les noms des fabricants de panneaux d’affichages concernés (lorsqu’on sait de qui il s’agit).
Outils en ligne de commande
Haiku est fourni avec un terminal et un shell bash (par défaut, d’autres shells peuvent également être utilisés). Les outils définis dans la spécification POSIX sont fournis, ainsi que des compléments permettant d’utiliser les fonctionnalités supplémentaires de Haiku.
df
La commande df affiche l’espace disque disponible sur chaque volume de stockage actuellement monté.
Les colonnes de l’affichage ont été réorganisées, pour être plus lisibles, et se rapprocher un peu du format spécifié par POSIX (mais pas complètement lorsqu’on lance la commande sans options particulières : des informations supplémentaires sont alors affichées).
filteredquery
L’outil filteredquery permet d’effectuer une requête sur les attributs étendus du système de fichiers (permettant de requêter le système de fichiers comme une base de données, plutôt que de naviguer de façon hiérarchique dans les dossiers), puis de filtrer le résultat pour ne conserver que les réponses contenues dans un sous-dossier spécifique. En effet, les requêtes étant indépendantes de l’organisation des dossiers, il est nécessaire de faire ce filtrage par post-traitement des résultats (ce qui reste tout de même généralement plus rapide que de faire l’inverse : parcourir tous les fichiers d’un dossier pour trouver ceux correspondant à un critère particulier).
Cet outil n’a pas reçu de nouvelles fonctionnalités, mais de nombreuses corrections et nettoyages qui le rendent véritablement utilisable.
ping, traceroute, telnet, ftpd
Ces commandes liées à des opérations sur le réseau ont été remplacées par les dernières versions développées par FreeBSD, permettant de bénéficier d’une version moderne, avec plus de fonctionnalités et moins de bugs.
La commande ping6 est supprimée, car ping peut maintenant utiliser l’IPv6 aussi bien que l’IPv4.
pkgman
L’outil pkgman permet de télécharger et d’installer des logiciels et des mises à jour.
Il a peu évolué, mais on peut tout de même noter l’utilisation d’un algorithme de tri « naturel » pour l’affichage des résultats dans l’ordre alphabétique (par exemple, llvm12 sera affiché après llvm9).
Une fonction qui n’est toujours pas disponible dans pkgman est le nettoyage des dépendances non utilisées. Un script fourni dans le dépôt Git de Haiku permet de réaliser manuellement une analyse des paquets installés sur le système pour détecter ceux qui n’ont pas de dépendances, il faudra pour l’instant se contenter de cette solution.
strace
L’outil strace permet d’afficher les appels systèmes effectués par une application, pour comprendre son interfaçage avec le noyau et investiguer certains problèmes de performances ou de mauvais comportements.
L’interfaçage avec le noyau pour extraire ces informations étant assez spécifique, l’implémentation de strace est faite à partir de zéro, et ne partage pas de code avec la commande du même nom disponible par exemple sous Linux.
strace est mis à jour régulièrement et en fonction des besoins des développeurs de Haiku pour décoder et afficher de plus en plus d’informations. Par exemple, elle peut maintenant afficher le contenu des iovec (par exemple pour les fonctions readv ou writev), ainsi que les objets manipulés par wait_for_object et event_queue.
Un exemple de sortie de strace (traçant l’ouverture d’un fichier et le chargement d’une bibliothèque partagée) avant ces changements:
open(0x5, "plaintext", 0x2042, 0x0) = 0x8000000f () (49 us)
map_file("libicuuc.so.66 mmap area", 0x7f04c2675228, 0x6, 0x1ababd0, 0x1, 0x0, true, 0x3, 0x0) = 0x329a0 () (108 us)
et après :
open(0x5, "plaintext", O_RDWR|O_NOTRAVERSE|O_CLOEXEC, 0x0) = 0x8000000f Operation not allowed (57 us)
map_file("libicuuc.so.66 mmap area", [0x0], B_RANDOMIZED_ANY_ADDRESS, 0x1ababd0, B_READ_AREA, 0x0, true, 0x3, 0x0) = 0x73e8 ([0x6392223000]) (135 us)
whence
La commande whence permettait de trouver dans le PATH un exécutable à partir de son nom. Elle était implémentée sous forme d’une fonction bash dans le fichier profile par défaut. Cependant, cette implémentation posait problème pour charger le fichier profile avec d’autres shells, elle a donc été supprimée. La commande which peut être utilisée à la place, puisqu’elle remplit un rôle équivalent.
Serveurs
Les serveurs sont l’équivalent des daemons pour UNIX ou des services sous Windows : il s’agit d’applications lancées par le système pour rendre différents services et coordonner l’ensemble des applications.
app_server
app_server est le serveur graphique de Haiku, équivalent de X ou de Wayland. Il se distingue par un rendu graphique fait principalement côté serveur (pour les applications natives), ce qui permet de l’utiliser de façon fluide à travers une connexion réseau.
Bien que ce soit le serveur graphique, et qu’il ait reçu plusieurs améliorations importantes, les différences sont subtiles. Elles sont toutefois importantes pour proposer un système qui semble réactif et confortable à utiliser.
Un premier changement est une réarchitecture du code qui traite le rafraîchissement de l’écran. Ce rafraîchissement se fait en général en plusieurs étapes, par exemple, si on déplace une fenêtre :
- Le contenu de la fenêtre déplacée peut être directement recopié de l’ancienne position vers la nouvelle,
- La zone où se trouvait la fenêtre auparavant doit être re-remplie avec ce qui se trouvait en dessous de la fenêtre déplacée. Cela peut être plusieurs morceaux de fenêtres d’autres applications, qui vont devoir chacune ré-afficher une partie de cette zone.
Le problème étant que certaines applications peuvent mettre un peu de temps à répondre à cette demande de ré-affichage (par exemple parce qu’elles sont occupées ailleurs, ou alors parce que la zone à redessiner est relativement complexe).
Différentes stratégies peuvent être mises en place dans ce cas : laisser à l’écran le contenu obsolète, ou remplir la zone en blanc en attendant que les données deviennent disponibles, par exemple. Ou encore, tout simplement ne rien mettre à jour du tout tant que tout l’écran n’est pas prêt à être affiché. Il faut faire un compromis entre la réactivité (déplacer la fenêtre tout de suite), la fluidité (éviter les clignotements de zones blanches) et la précision (affichage d’information cohérente et à jour).
Plusieurs modifications ont permis d’obtenir un meilleur compromis.
Dans un autre domaine, la police de caractères par défaut « Noto Sans Display » a été remplacée par « Noto Sans », ce qui donne un affichage du texte légèrement différent. La police « display » avait été choisie suite à une mauvaise compréhension de la signification de ce mot en typographie : il signifie que c’est une police de caractères à utiliser pour des gros titres et autres textes courts. Il ne signifie pas que c’est une police à utiliser sur un écran d’ordinateur. De toutes façons la police Noto Display n’est plus maintenue par Google et a disparu des dernières versions du jeu de polices Noto.
Toujours dans le domaine des polices de caractères, app_server sait maintenant charger les fichiers « variable fonts ». Ces fichiers contiennent plusieurs polices de caractères définies à partir de glyphes de base, et d’algorithmes de transformation et de déformation (pour rendre une police plus ou moins grasse, plus ou moins italique…). Pour l’instant, app_server sait charger les valeurs de ces paramètres qui sont préconfigurées dans le fichier. Cela permet de réduire la place utilisée par les polices de caractères sur le media d’installation de Haiku (c’est l’un des plus gros consommateurs d’espace disque, qui nous empêche de faire tenir une version complète de Haiku sur un CD de démonstration par exemple).
Plus tard, il sera également possible de configurer plus finement ces paramètres pour générer des variantes intermédiaires des polices de caractères, ainsi que d’exploiter certaines polices qui offrent des paramètres configurables supplémentaires.
input_server
L’input_server se charge de lire les données venant des périphériques d’entrée (clavier et souris) et de les convertir en évènements distribués aux applications. Il est extensible par des add-ons qui peuvent générer ou filtrer des évènements, ce qui peut être utilisé pour de l’accessibilité (émuler une souris à partir de touches du clavier), de l’automatisation (envoi de commandes pré-enregistrées), du confort d’utilisation (bloquer le touchpad d’un ordinateur portable lorsque le clavier est en cours d’utilisation) et bien d’autres choses.
L’input_server a reçu des corrections de problèmes sur la gestion des réglages de souris, permettant en particulier d’utiliser des réglages différents pour plusieurs périphériques (souris, touchpad), et que ceux-ci soient bien enregistrés.
registrar
Le serveur registrar suit les applications en cours de fonctionnement, et leur permet de communiquer entre elles au travers de l’envoi de messages. Il assure également le suivi de la base de données des types MIME et des associations de types de fichiers avec les applications correspondantes.
L’implémentation de BMessageRunner, qui permet d’envoyer des messages périodiques (par exemple pour faire clignoter le curseur des zones de texte à la bonne vitesse), autorise maintenant des intervalles de répétition en dessous de 50 millisecondes. Cela permet d’utiliser ce système pour des animations fluides de l’interface graphique, par exemple.
D’autre part, la liste des applications et documents récemment lancés est maintenant limitée à 100 entrées. Cela évite un fichier qui grossit indéfiniment et finit par contenir surtout des vieilles informations sans intérêt.
Kits
Le système Haiku fournit les mêmes APIs que BeOS. Elles couvrent les usages basiques d’une application, et sont découpées (dans la documentation de BeOS et de Haiku, au moins) en « kits » qui prennent chacun en charge une partie spécifique (interface graphique, multimédia, jeux vidéos, accès au matériel, etc).
Interface
L’interface kit est la partie de la bibliothèque standard qui se charge des interfaces graphiques.
BColumnListView
BColumnListView est un ajout de Haiku par rapport à BeOS. Il s’agit d’un élément d’interface permettant de présenter une liste avec plusieurs colonnes, de trier les lignes selon le contenu de ces colonnes, et aussi d’avoir des items hiérarchisés avec la possibilité de plier et déplier une partie de l’arborescence.
Cette classe remplace avantageusement BListView et surtout BColumnListView, les classes historiques de BeOS, qui sont beaucoup plus limitées.
Un certain nombre de type de colonnes prédéfinis sont également disponibles, ce qui facilite la construction d’interfaces présentant les données de différentes applications avec le même formatage.
La classe BColumnListView elle-même n’a pas changé. Par contre, les colonnes de type « taille » (pour afficher une taille en Kio, Mio, Gio…) et « date » utilisent la langue choisie dans les préférences système au lieu d’un format anglais par défaut.
BTextView
BTextView est une classe permettant d’afficher une zone de texte éditable. Elle implémente les fonctionnalités de base (curseur, sélection, retour à la ligne automatique) ainsi que quelques possibilités de mise en forme (couleurs, polices de caractères).
BTextView peut également être utilisée pour des zones de textes non éditables, souvent plus courtes. Cela permet de réutiliser une partie des algorithmes de mise en page et de formatage du texte dans différents contextes. Dans le cadre de l’utilisation du « layout system », une vue doit pouvoir indiquer sa taille minimale, maximale et optimale. Le « layout system » va ensuite calculer la meilleure disposition de fenêtre possible pour satisfaire ces contraintes.
Le cas des zones de texte est particulier, car la hauteur optimale dépend du nombre de lignes de texte, qui lui-même peut être plus ou moins grand si la largeur de la vue oblige à ajouter des retours à la ligne. Le « layout kit » prend en compte ce cas particulier, mais les algorithmes ne sont pas encore tout à fait au point et peuvent conduire à des résultats inattendus dans certains cas. Un de ces cas particuliers sur les zones de texte non éditables a été corrigé.
BMenu
La classe BMenu permet d’afficher un menu. Elle est utilisée de plusieurs façons, puisqu’on trouve des menus dans des barres de menu, dans des contrôles de type « popup », ou encore en faisant un clic droit sur certains éléments de l’interface.
Les menus sont également particuliers parce qu’ils peuvent d’étendre en dehors de la fenêtre dont ils sont originaires. Ils sont donc implémentés sous forme de fenêtres indépendantes. Mais cela pose un autre problème : dans Haiku, chaque fenêtre exécute son propre thread et sa propre boucle d’évènements. Si on navigue dans un grand nombre de menus et de sous-menus, cela peut causer quelques problèmes de synchronisation et de performances.
Le code contient également un grand nombre de cas particuliers pour, par exemple, aligner les raccourcis claviers et les flèches indiquant la présence de sous-menus ente les différents items d’un menu, ou encore détecter si un déplacement de souris a pour but de sélectionner un autre menu (en dessous ou au-dessus de celui actif), ou bien plutôt de naviguer vers un sous-menu.
Les nouveautés suivantes sont apparues cette année:
- Correction de problèmes de race condition lors de l’ajout d’items dans un menu pendant qu’il est affiché à l’écran. Ce problème se manifestait par exemple dans les menus affichant la liste des réseaux Wifi, qui sont mis à jour en temps réel.
- Finalisation de l’implémentation de la navigation au clavier (avec les flèches directionnelles) dans les menus.
- Affichage des symboles graphiques UNICODE pour « backspace » (⌫) et « delete » (⌦) si ces touches sont utilisées comme raccourcis clavier pour un item de menu.
- Utilisation d’un algorithme de tri stable pour la fonction
SortItems. Ce type d’algorithme préserve l’ordre relatif des items qui sont égaux d’après la fonction de comparaison. Ce n’est pas le cas de certains algorithmes de tri classiques, notamment le quicksort. La conséquence était que trier un menu déjà trié pouvait changer l'ordre des items. C’était visible encore une fois sur le menu listant les réseaux Wifi, qui est trié par puissance du signal reçu.
BSpinner
BSpinner est un contrôle permettant de choisir une valeur numérique, soit à l’aide de boutons +/- pour modifier la valeur par incréments, soit en entrant directement la valeur dans une zone de texte.
Il s’agit d’une extension de Haiku par rapport à BeOS qui ne proposait pas cette fonctionnalité.
Cette classe est encore en cours de développement. Elle a reçu des améliorations pour désactiver correctement les boutons +/- lorsque la valeur atteint le minimum ou le maximum autorisé, et aussi une correction sur le message de notification envoyé lors des changements de valeurs du spinner, qui ne contenaient pas la bonne valeur.
rgb_color
La structure rgb_color permet de représenter une couleur par la valeur de ses composantes rouge, vert, bleu (comme son nom l’indique) et alpha (comme son nom ne l’indique pas). Elle fournit également un certain nombre de fonctions pour mélanger des couleurs, les éclaircir ou les assombrir.
La méthode Brightness() dans la classe rgb_color implémentante maintenant l’algorithme perceptual brightness documenté par Darel Rex Finley, qui donne des meilleurs résultats que l’algorithme utilisé précédemment (qui était celui de la luminosité dans l’espace de couleurs Y'IQ. La fonction perceptual_brightness devenue redondante est supprimée.
Cette méthode permet en particulier de déterminer si une couleur est « sombre » ou « claire », et ainsi de décider si du texte affiché par-dessus doit être blanc ou noir (comme démontré ici par exemple).
Locale
Le locale kit se charge de tous les aspects liés à la localisation : traductions des applications, formatage des messages en utilisant les règles de pluralisation de chaque langue, formatage de dates, de nombres avec et sans unités, de pourcentages, nom des fuseaux horaires…
Il utilise ICU pour implémenter la plupart de ces fonctionnalités, mais fournit une surcouche avec une API s’intégrant mieux avec les autres kits.
La principale évolution cette année est l’implémentation de BNumberFormat, qui permet de formater des nombres. Elle permet de choisir une précision (nombre de décimales - pour les langues qui utilisent un système décimal), d’afficher ou non des séparateurs de groupes (de milliers en français, mais par exemple en Inde la séparation se fait traditionnellement par multiples de 10 000).
Media
Le media kit se charge de tous les aspects multimedia.
Il se compose de deux parties. D’une part, un système de gestion de flux média temps réel, permettant de transférer des données multimédia (son ou flux vidéo par exemple) entre différentes applications qui vont les manipuler, le tout avec un certain contrôle du temps de traitement ajouté par chaque opération, pour tenter de minimiser la latence tout en évitant les vidages de tampons qui produiraient une interruption dans le flux. D’autre part, des classes permettant d’encoder et de décoder des fichiers média et d’en extraire des flux de données (encodées ou décodées).
C’est surtout cette deuxième partie qui a reçu quelques évolutions. La version de ffmpeg utilisée pour le décodage de presque tous les formats audio et video est maintenant la dernière version ffmpeg 6. Quelques autres problèmes (erreurs d’arrondis, gestion des tampons partiels en fin de fichier) ont également été corrigés, ce qui permet de faire fonctionner à nouveau le jeu BePac Deluxe qui est extrêmement intolérant au moindre écart de comportement par rapport à l’implémentation du Media Kit dans BeOS.
Support
Le support kit contient un ensemble de classes basiques mais indispensables : gestion des chaînes de caractères, des tampons en mémoire, etc. Il fournit les briques de bases utilisées par les autres kits.
BDataIO
BDataIO est une classe abstraite avec des fonctions de lecture et d’écriture. Plusieurs autres classes sont des instances de BDataIO, par exemple BFile (représentant un fichier), mais aussi BMemoryIO (permettant d’accéder à une zone mémoire).
Plusieurs autres classes acceptent BDataIO (ou sa sous-classe BPositionIO, qui ajoute la possibilité de se déplacer à une position donnée dans le flux) comme entrée ou comme sortie. Il est donc facilement possible de réaliser les mêmes opérations sur un fichier, une zone de données en mémoire, un socket réseau, ou tout autre objet susceptible de fournir une interface similaire.
BDataIO elle-même n’a pas évolué, mais deux de ses implémentations, BBufferedDataIO et BAdapterIO, ont été améliorées. Ces deux classes permettent de construire un objet BDataIO à partir d’un autre, en ajoutant un cache en mémoire pour accélérer les opérations ou encore pour rendre compatible avec BPositionIO un objet qui ne l’est pas.
Ces classes sont en particulier utilisées par l’application StreamRadio, qui implémente la lecture de podcasts en connectant directement le résultat d’une requête HTTP (effectuée grace au network kit) dans un décodeur audio (via la classe BMediaFile du media kit). La mise en tampon permet de revenir en arrière dans la lecture d’un épisode, de télécharger en avance les données qui vont être lues, et d’éviter de conserver inutilement en mémoire les données qui sont déjà lues par l’application.
Bibliothèques C
Les « kits » mentionnés ci-dessus sont l’API en C++ utilisée par les applications Haiku.
Il existe aussi des APIs en C, en grande partie implémentant la bibliothèque C standard et les fonctions décrites dans la spécification POSIX.
Libroot
Libroot implémente la bibliothèque standard C. Elle regroupe entre autres la libc, la libm, et la libpthread, qui sont parfois implémentées comme 3 bibliothèques différentes pour d’autres systèmes. Les évolutions consistent à compléter l’implémentation de la spécification POSIX, et à suivre les évolutions de cette dernière ainsi que des nouvelles versions du langage C. On trouve également des corrections de bugs découverts en essayant de faire fonctionner de plus en plus d’applications sur Haiku, ce qui permet de mettre en évidence des différences de comportement avec d’autres systèmes.
- Ajout de
getentropy pour initialiser les générateurs de nombres aléatoires
- Correction de problèmes de locks au niveau de l’allocateur mémoire lors d’un fork
- Plusieurs corrections sur l’implémentation de
locale_t, remplacement de code écrit pour Haiku ou provenant de FreeBSD par une implémentation simplifiée mais suffisante, provenant de la bibliothèque C musl.
- Ajout de
static_assert en C11
- Correction d’un crash lors de l’utilisation de certaines fonctions XSI
- Ajout de
stpncpy
- La fonction
open utilisée sur un lien symbolique pointant vers un fichier non existant peut maintenant créer le fichier cible.
- Il est possible d’utiliser
mmap sur un fichier plus grand que la mémoire disponible sans avoir besoin de spécifier le flag MAP_NORESERVE
- Utiliser
rename pour renommer un fichier vers lui-même ne retourne plus d’erreur (conformément à la spécification POSIX).
- Ajout de
pthread_sigqueue
Libnetwork
La libnetwork implémente les APIs nécessaire pour se connecter au réseau (sockets, résolution DNS…). Elle est séparée de la bibliothèque C pour des raisons historiques : l’implémentation de TCP/IP pour BeOS avait été réalisée entièrement en espace utilisateur (le noyau n’offrant qu’une interface pour envoyer et recevoir des paquets ethernet sur la carte réseau). Cela a posé des problèmes de compatibilité avec d’autres systèmes, et des problèmes de performance. Haiku est donc compatible avec la version "BONE" de BeOS, qui implémente la pile réseau dans le noyau.
- Mise à jour du résolveur DNS à partir du code de NetBSD 9.3. Précédement le code utilisé était celui du projet netresolv de NetBSD, mais ce projet n’a pas connu de nouvelles publications et le code est à nouveau maintenu directement dans NetBSD sans publication séparée.
- Correction d’un crash lors de l’utilisation de multicast IPv4
LibBSD
La libbsd implémente plusieurs extensions fournies par la libc de certains systèmes BSD. Elle est séparée de la bibliothèque C principale pour limiter les problèmes de compatibilité: certaines applications préfèrent fournir leur propre version de ces fonctions, ou d’autres fonctions avec le même nom mais un comportement différent. Elles peuvent alors s’isoler en n’utilisant pas la libbsd pour éviter toute interférence.
LibGNU
De façon similaire à la libbsd, la libgnu fournit des fonctions qui sont disponibles dans la glibc (la bibliothèque C du projet GNU) mais ne font pas partie d’un standard (C ou POSIX).
- Ajout de
sched_getcpu pour savoir sur quel cœur de CPU le thread appelant est en train de s’exécuter.
- Ajout de
pthread_timedjoin_np, pour attendre la fin de l’exécution d’un thread (comme pthread_join mais avec un timeout.













































































{kind=link}