Sommaire
Rapport financier 2024
Recettes
L’association Haiku inc (association de type 501(c)3 aux USA) publie chaque année un rapport financier. Le rôle de l’association est de récolter les dons et de les redistribuer pour aider au développement de Haiku. Elle ne prend pas part aux décisions techniques sur l’orientation du projet, et habituellement les dépenses sont faites en réponse aux demandes des développeurs du projet.
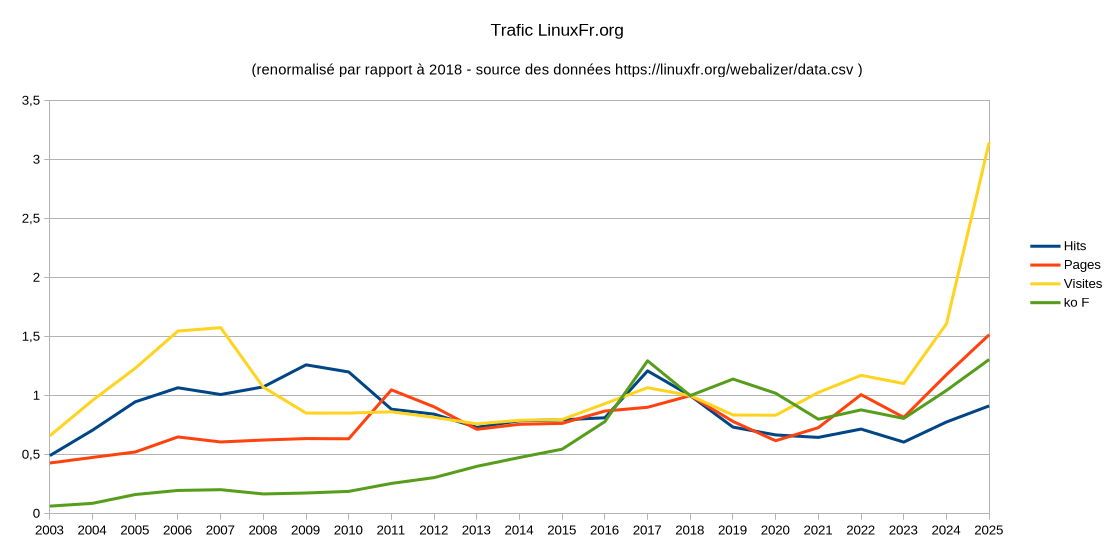
L’objectif en début d’année 2024 était de récolter 20 000$ de dons. Cet objectif a été largement atteint, il a dû être mis à jour 2 fois en cours d’année et finalement ce sont plus de 31 000$ qui ont été reçus ! Cela en particulier grace à un assez gros don de 7 500$.
Les dons sont récoltés via différentes plateformes: Github Sponsors (intéressant, car il n’y a aucun frais de traitement), PayPal, Liberapay, Benevity (une plateforme de « corporate matching »), ainsi que des paiements par chèque, virements bancaires, et en espèce lors de la tenue de stands dans des conférences de logiciels libres. La vente de T-Shirts et autre merchandising via la boutique Freewear reste anecdotique (une centaine de dollars cette année).
Il faut ajouter à ces dons une contribution de 4 400$ de la part de Google en compensation du temps passé à l’encadrement des participants au Google Summer of Code.
Il faut également ajouter des dons en crypto-monnaies, principalement en bitcoins. Le rapport financier présente les chiffres en détail en tenant une compatibilité séparée en dollars, en euros, et en crypto-monnaies, avant de convertir le total en dollars pour dresser un bilan complet.
Une mauvaise nouvelle tout de même: le service de microdons Flattr a fermé ses portes. L’entreprise propose maintenant un service de bloqueur de publicités payant, qui reverse de l’argent aux sites dont les publicités sont bloquées.
Le compte Flattr de Haiku avait été créé pour recevoir des dons sur la plateforme, mais n’avait jamais été configuré pour transférer ces dons vers le compte en banque de l’association. Malgré un certain temps passé à discuter avec le service client de Flattr et à leur fournir tous les documents demandés, il n’a pas été possible de trouver une solution pour récupérer cet argent. Ce sont donc 800$ qui ne reviendront finalement pas au projet Haiku.
Au final, les recettes sont de 36 479 dollars, de loin la plus grosse somme reçue par le projet en un an.
Dépenses
La dépense principale est le paiement de Waddlesplash, le développeur actuellement employé par Haiku inc pour accélérer le développement du système (les autres développeurs participent uniquement sur leur temps libre, en fonction de leurs autres activités). Cela représente 25 500$, un coût assez faible par rapport au travail réalisé.
Le deuxième poste de dépenses est l’infrastructure, c’est-à dire le paiement pour l’hébergement de serveurs, les noms de domaines, et quelques services « cloud » en particulier pour le stockage des dépôts de paquets.
Le reste des dépenses consiste en frais divers (commission PayPal par exemple), remboursement de déplacements pour la participation à des conférences, ainsi que le renouvellement de la marque déposée sur le logo Haiku.
Le total des dépenses s’élève à 31 467$. C’est moins que les recettes, et l’association continue donc de mettre de l’argent de côté. L’année 2022 a été la seule à être déficitaire, suite au démarrage du contrat de Waddlesplash. Ce contrat est à présent couvert par les donations reçues.
Réserves
L’association dispose de plus de 100 000$ répartis sur son compte en banque, un compte PayPal (qui permet de conserver des fonds en euros pour les paiements en euros et ainsi d’éviter des frais de change), et un compte Payoneer (utilisé pour recevoir les paiements de Google).
Elle dispose également de près de 350 000$ en crypto-monnaies dont la valeur continue d’augmenter. Cependant, actuellement ces fonds ne sont pas accessibles directement, en raison de problèmes administratifs avec Coinbase, l’entreprise qui gère ce portefeuille de crypto-monnaies. Le compte n’est pas configuré correctement comme appartenant à une association à but non lucratif et cela pose des problèmes de déclaration de taxes lorsque on souhaite vendre des crypto-monnaies contre du vrai argent. Cette situation persiste depuis plusieurs années, mais l’association n’a pour l’instant pas besoin de récupérer cet argent, les réserves dans le compte en banque principal étant suffisantes.
Applications
Iceweasel
Le navigateur web Iceweasel est disponible dans les dépôts de paquets (seulement pour la version 64 bits pour l’instant). Il s’agit d’un portage de Firefox utilisant la couche de compatibilité Wayland. Le nom Firefox ne peut pas être utilisé puisqu’il ne s’agit pas d’un produit officiel de Mozilla.
En plus du travail de portage pour réussir à faire fonctionner le navigateur, cela a nécessité un gros travail d’amélioration au niveau de la gestion de la mémoire, une partie du système qui est fortement mise à contribution par ce navigateur. On en reparle plus loin dans la dépêche.
Le navigateur est encore considéré comme expérimental: plusieurs fonctions sont manquantes et il peut y avoir des plantages. WebPositive (le navigateur natif basé sur WebKit) reste donc le navigateur installé par défaut avec Haiku, mais les deux sont complémentaires. Par exemple, Iceweasel permet d’afficher les vidéos Youtube avec des performances acceptables.
Tracker
Tracker est le gestionnaire de fichiers de Haiku. Il implémente une interface « spatiale », c’est-à-dire que chaque dossier s’ouvre dans une fenêtre séparée et enregistre sa position à l’écran.
Le code du Tracker fait partie des composants qui ont pu être récupérés de BeOS. Cela signifie que certaines parties du code ont été développées il y a près de 30 ans, dans un contexte où l’élégance du code n’était pas la priorité (il fallait pour les développeurs de BeOS, d’une part livrer un système fonctionnel dans un temps raisonable, et d’autre part, fonctionner sur les machines relativement peu performantes de l’époque).
Les évolutions sur le Tracker nécessitent donc souvent du nettoyage dans de nombreuses parties du code, et provoquent souvent des régressions sur d’autres fonctionnalités. Toutefois, les choses s’améliorent petit à petit.
Ce trimestre, on a vu par exemple arriver la correction d’un problème avec l’utilisation de la touche « echap ». Cette touche peut servir à plusieurs choses:
- Fermer une fenêtre de chargement ou d’enregistrement de fichier,
- Annuler le renommage d’un fichier,
- Annuler une recherche rapide « type ahead » qui consiste à taper quelques lettres et voir immédiatement la liste de fichiers du dossier courant se réduire à ceux qui contiennent cette chaîne de caractères.
Ces différentes utilisations peuvent entrer en conflit. Plus précisément, lorsqu’on utilise le filtrage « type ahead », puis qu’on change d’avis et qu’on appuie sur la touche « echap », il ne faut pas que cela ferme la fenêtre en même temps.
Un autre changement concerne plutôt la validation des données: Tracker interdit l’insertion de caractères de contrôle ASCII dans le nom de fichiers. Ce n’est pas strictement interdit (ni par Haiku, ni par ses systèmes de fichiers, ni par POSIX) en dehors de deux caractères spéciaux: le '/' et le 0 qui termine une chaîne de caractères. Mais, c’est très probablement une mauvaise idée d’avoir un retour à la ligne ou un autre caractère de contrôle enregistré dans un nom de fichier. Le Tracker interdit donc désormais de le faire et si vous êtes vraiment résolu à y parvenir, il faudra passer par le terminal.
Enfin, une nouvelle fonctionnalité dans le Tracker est la mise à jour en temps réel des menus pop-up. Cela peut se produire pour plusieurs raisons, par exemple, l’appui sur la touche « command » modifie le comportement de certains menus. Avant ce changement, il fallait ré-ouvrir le menu (command + clic droit) pour voir ces options modifiées. Maintenant, on peut d’abord ouvrir le menu, puis maintenir la touche command enfoncée pour voir les options modifiées.
Cela a nécessité une refonte complète de la gestion de ces menus (qui proposent de nombreuses autres choses comme la navigation « rayons X »). Au passage, certaines options qui étaient uniquement disponibles au travers de raccourcis claviers ou de la barre de menu des fenêtres du Tracker sont maintenant aussi affichées dans le menu pop-up.
TeamMonitor
TeamMonitor est le gestionnaire d’applications affiché quand on utilise la combinaison de touches Ctrl+Alt+Suppr. Il permet de stopper des programmes, de redémarrer la machine, et autres manipulations d’urgence si le système ne fonctionne pas comme il faut.
Les processus lancés par une même application sont maintenant regroupés et peuvent être tous arrêtés d’un seul coup. Ce changement est nécessaire suite à l’apparition de IceWeasel, qui crée beaucoup de processus en tâche de fond pour une seule instance du navigateur web.
HaikuDepot
HaikuDepot est l’interface graphique pour le système de paquets de Haiku. Il se présente comme un magasin d’applications, permettant non seulement d’installer et de désinstaller des logiciels, mais aussi de les évaluer avec une note et un commentaire.
- Ajout d’un marqueur sur les icônes des paquets qui sont déjà installés, et remplacement du marqueur utilisé pour indiquer les applications « natives » (utilisant le toolkit graphique de Haiku, par opposition à Qt et GTK par exemple).
- Affichage plus rapide de l’état « en attente d’installation » lorsqu’on demande l’installation d’un paquet.
- L’interface pour noter un paquet est masquée si l’attribution de notes n’est pas possible.
Préférences
Diverses améliorations dans les fenêtres de préférences:
- Correction d’un crash dans les préférences d’affichage (korli).
- Les préférences de fond d’écran n’acceptent plus le glisser-déposer d’une couleur sur un contrôle de choix de couleur désactivé. La modification de la position X et Y de l’image de fond se met à jour en temps réel quand on édite la valeur des contrôles correspondants.
- Ajout de réglages supplémentaires (vitesse, accélération, défilement) dans les préférences des pavés tactiles. Ces options étaient déjà implémentées dans l’input_server, mais configurable uniquement pour les souris.
- Suppression de code mort et amélioration de la gestion des polices de caractères dans les préférences d’apparence.
Plusieurs améliorations sur les préférences de sons de notifications:
- La fenêtre de sélection de fichiers retient le dernier dossier utilisé,
- Elle permet également d’écouter un son avant de le sélectionner,
- Les menus de sélection rapide de sons affichent uniquement les fichiers et pas les dossiers,
- Certains sons ont été renommés.
La plupart des sons ne sont cependant toujours pas utilisés par le système.
Expander
Expander est un outil permettant d’extraire plusieurs types de fichiers archivés.
Peu de changement sur cet outil qui est assez simple et fonctionnel. La seule amélioration ce mois-ci concerne un changement des proportions de la fenêtre pour éviter un espace vide disgracieux.
Cortex
Cortex est une application permettant de visualiser et de manipuler les nœuds de traitement de données du Media Kit.
Le composant « logging consumer » qui reçoit des données d’un autre noeud et les enregistre dans un fichier de log pour analyse a été amélioré pour enregistrer un peu plus d’informations.
Icon-O-Matic
L’éditeur d’icônes vectoriels Icon-O-Matic évolue peu, après un projet Google Summer of Code qui a ajouté la plupart des fonctionnalités manquantes. Ce trimestre, un seul changement: l’ajout d’une entrée menu pour supprimer un « transformeur ».
PowerStatus
L’application PowerStatus affiche l’état de la batterie. Cela peut se présenter comme une icône dans la barre des tâches. L’icône est de taille réduite, et les différents états n’étaient pas forcément bien visibles. Ce problème a été corrigé avec des nouveaux marqueurs pour l’état de la batterie (en charge ou inactive).
StyledEdit
StyledEdit est un éditeur de texte simple, permettant tout de même de formater le texte (un peu comme WordPad pour Windows).
L’application reçoit une nouvelle option pour écrire du texte barré. Le code nécessaire a également été ajouté dans app_server, puisque cette possibilité était prévue, mais non implémentée.
WebPositive
Le navigateur WebPositive reçoit peu d’évolutions en ce moment, en dehors de la maintenance du moteur WebKit. On peut tout de même mentionner l’ajout d’un menu contextuel sur les marque-pages, permettant de les renommer et de les supprimer. Ce développement est issu d’un vieux patch réalisé par un candidat au Google Summer of Code, qui ne fonctionnait pas et n’avait jamais été finalisé.
Mode sombre et configuration des couleurs
Depuis la version Beta 5, Haiku dispose d’un nouveau système de configuration des couleurs, permettant d’obtenir facilement un affichage en « mode sombre ». Cependant, cet affichage est loin d’être parfait, et de petits ajustements sont à faire petit à petit dans toutes les applications qui n’avaient pas été pensées pour cela. En particulier, le changement de couleurs se fait en direct lorsqu’on change les réglages. On trouve ces trois derniers mois des changements dans DeskBar, Tracker, HaikuDepot, l’horloge, ainsi que la classe BTextView.
Outils en ligne de commande
pkgman peut rechercher les paquets installés et qui n’ont aucun autre paquet dépendant d’eux. Cela permet de trouver des paquets inutiles qui peuvent être désinstallés (il manque encore la possibilité de marquer un paquet comme étant « installé manuellement » avant de pouvoir automatiser le nettoyage).
La commande route accepte la syntaxe utilisée par openvpn pour la configuration d’une route par défaut, ce qui facilite l’utilisation de VPN avec Haiku.
Correction d’un problème dans le compilateur de ressources: la commande rc -d ne savait pas décompiler la structure app_version des applications Haiku, uniquement le format plus ancien utilisé par BeOS.
La commande screenmode permet maintenant de récupérer la valeur actuelle du réglage du rétro-éclairage (en plus de permettre de changer cette valeur).
Kits
La bibliothèque de fonctions de Haiku est découpée en « kits » qui regroupent un ensemble de classes et de fonctionnalités liées.
Application kit
L’Application Kit permet, comme son nom l’indique, de lancer des applications. Il offre également toutes les fonctionnalités de boucles d’évènements, et d’envoi de messages entre applications et entre composants d’une application.
Correction d’un problème de suppression d’un port dans la classe BApplication.
Debug kit
Le Debug Kit fournit les services nécessaires au Debugger pour débugger une application. Cela consiste d’une part en un accès privilégie à l’espace mémoire d’une application, et d’autre part en outils pour analyser les fichiers ELF des exécutables et bibliothèques.
Le Debug Kit reçoit ce trimestre plusieurs évolutions et corrections permettant le décodage des stack traces dans les programmes compilés avec clang et lld. Par exemple, les fichiers ELF générés par ces outils sont découpés en plusieurs segments, alors que ce n’est pas le cas pour gcc.
Device Kit
Le Device Kit regroupe tout ce qui concerne l’accès direct au matériel et aux entrées-sorties depuis l’espace utilisateur: ports série, accès direct aux périphériques USB, accès aux joysticks et manettes de jeu.
Les ports série RS232 peuvent être configurés avec des valeurs en baud personnalisées (pour l’instant uniquement pour les adaptateurs série USB).
Interface kit
L’Interface Kit regroupe tout ce qui concerne l’affichage de fenêtres et de vues à l’écran et les interactions avec ces fenêtres.
- Ajout de constructeur « move » et d’opérateur d’assignation pour
BRegion et BShape pour améliorer les performances en évitant les copie d’objet immédiatement suivies de suppression.
- Ajout d’un constructeur pour
BRect avec deux arguments (largeur et hauteur) pour les rectangles alignés en haut à gauche ou dont la position n’a pas d’importance.
- Remise en place d’un cas particulier dans
BBitmap::SetBits pour la gestion du canal alpha afin d’avoir un comportement plus proche de celui de BeOS.
- BColorControl réagit correctement et déclenche les évènements nécessaires lorsqu’on modifie sa couleur par glisser-déposer.
Media Kit
Correction d’une assertion vérifiant la mauvaise condition dans BTimeSource.
Réécriture de la classe BTimedEventQueue pour améliorer ses performances en évitant d’allouer de la mémoire dynamique.
Amélioration de l’affichage des « media controls » (sliders de contrôle de volume par exemple) en mode sombre.
libshared
La « libshared » contient plusieurs classes expérimentales, en cours de développement, mais déjà utilisées par plusieurs applications. Il s’agit d’une bibliothèque statique, ce qui permet de changer facilement son contenu sans casser l’ABI des applications existantes.
Ajout de la classe ColorPreview qui existait en plusieurs exemplaires dans le code de Haiku (préférences d’apparence et Terminal). Cette classe permet d’afficher une couleur dans un petit rectangle. Elle est utilisée à plusieurs endroits dans des contrôles de choix de couleur plus complexes, tels que des listes ou des menus.
Servers
Les servers sont des processus systèmes implémentant différentes fonctionnalités de Haiku. Le concept est similaire à celui des daemons dans UNIX, ou des services dans Windows NT et systemd.
app_server
L’app_server s’occupe de l’affichage des applications à l’écran.
Suppression de code inutilisé depuis longtemps permettant l’accélération matérielle d’opérations de dessin en 2D (blit, tracé de lignes, remplissage de rectangles…).
Sur les cartes graphiques PCI, ces opérations étaient souvent réalisées plus rapidement par le CPU qui tourne à une fréquence bien plus rapide que la carte. Sur les cartes AGP, l’accès en lecture à la mémoire vidéo par le CPU est très lent, et il était donc plus intéressant de faire ces opérations en RAM centrale avant d’envoyer un buffer prêt à afficher à la carte graphique. Enfin sur les cartes PCI express modernes, ces fonctions d’accélération ont disparu ou en tout cas n’ont pas du tout une interface compatible avec les besoins de Haiku. Il est donc temps de jeter ce code.
Modification de la façon dont les applications récupèrent la palette de couleurs en mode graphique 256 couleurs: elle utilise maintenant une mémoire partagée, et il n’est plus nécessaire que chaque application demandent au serveur graphique d’en obtenir une copie.
input_server
L’input_server se charge des entrées souris et clavier. Cela comprend les méthodes d’entrée de texte (par exemple pour le Japonais) ainsi que des filtres permettant de manipuler et d’intercepter ces évènements d’entrée avant leur distribution dans les applications.
Améliorations du filtre PadBlocker pour bloquer le touchpad quand le clavier est en cours d’utilisation sur les PC portables: gestion des répétitions de touches, blocage uniquement du touchpad et pas des autres périphériques de pointage.
net_server
Le net_server se charge de la configuration des interfaces réseau.
Arrêt du client d’autoconfiguration (DHCP par exemple) lors de la perte du lien sur un port Ethernet, pour ne pas essayer d’envoyer des paquets alors que le câble est débranché.
notification_server
notification_server se charge de l’affichage de panneaux de notification pour divers évènements tels que la connexion et déconnexion d’interfaces réseau, un niveau dangereusement bas de la batterie, la fin d’un téléchargement…
La fenêtre de notification a été retravaillée pour mieux s’adapter à la taille de police d’affichage choisie par l’utilisateur.
mail_daemon
mail_daemon permet d’envoyer et de recevoir des e-mails. Les messages sont stockés sous forme de fichiers avec des attributs étendus pour les métadonnées (sujet, expéditeur…). Plusieurs applications clientes permettent de rédiger ou de lire ces fichiers. Ainsi chaque application n’a pas besoin de réimplémenter les protocoles IMAP ou SMTP.
Amélioration de la fenêtre de logs pour la compatibilité avec le mode sombre.
runtime_loader
Le runtime_loader est l’outil qui permet de démarrer un exécutable. Il se charge de trouver toutes les bibliothèques partagées nécessaires et de les placer dans la mémoire.
Ajout du flag PF_EXECUTE qui rend exécutable uniquement les sections ELF qui le nécessitent (auparavant, toutes les sections qui n’étaient pas accessibles en écriture étaient exécutables). Cela est utilisé en particulier par clang, qui sépare une zone en lecture seule (pour les constantes) et une autre en lecture et exécution (pour le code). Avec gcc, les deux sont habituellement regroupées dans la même section.
Drivers
Périphériques de stockage
Correction de bugs dans la couche SCSI (utilisée également pour d’autres périphériques de stockage qui encapsulent des commandes SCSI). Des drapeaux d’état n’étaient pas remis à 0 au bon moment, ce qui causait des kernel panic avec le message « no such range! ».
Cela a été l’occasion de faire du ménage : suppression de champs inutilisés dans des structures de données, et suppression du module d’allocation mémoire locked_pool qui n’était utilisé que par la pile SCSI. À la place, utilisation des fonctions d’allocation mémoire standard du noyau, qui sont amplement suffisantes pour répondre aux besoins de ce module (waddlesplash).
Cartes son
Correction d’erreurs dans le code de gestion mémoire des pilotes es1370 et auvia. Ces drivers utilisaient deux copies d’un code d’allocation identique, mais avaient divergé l’un de l’autre. Ils ont été réunifiés mais cela a provoqué quelques régressions, avec des difficultés pour trouver des machines permettant de tester chacune des cartes son concernées. Haiku peut heureusement compter sur des utilisateurs « avancés » qui testent régulièrement les nightly builds pour détecter ce type de régression (korli).
Réseau
Correction d’une fuite mémoire lors de l’utilisation de sockets « raw » permettant d’envoyer et de recevoir directement des paquets ethernet (en contournant la couche IP).
Pilotes FreeBSD
Une grande partie des pilotes de carte réseau de Haiku sont en fait ceux de FreeBSD ou d’OpenBSD. Une couche de compatibilité permet de réutiliser ces pilotes avec très peu de changement dans leur code source. Ainsi, les évolutions et corrections peuvent être partagées avec l’un ou l’autre de ces systèmes. La collaboration avec les *BSD pour les pilotes réseau se passe de mieux en mieux : suite au développement d’une couche de compatibilité permettant d’utiliser les pilotes OpenBSD dans Haiku, les développeurs de FreeBSD étudient la possibilité de réutiliser également ces pilotes. De plus, les développeurs de Haiku et d’OpenBSD sont en contact pour coordonner les mises à jour et les tests.
Génération de statistiques plus fiables sur les paquets réseaux dans la couche de compatibilité FreeBSD et remontée des statistiques générées par les pilotes associés.
Synchronisation du pilote realtekwifi avec la version de FreeBSD et reconnaissance d’un identifiant de périphérique USB supplémentaire dans ce pilote.
Amélioration de la couche de compatibilité pour se comporter plus précisément comme FreeBSD, et suppression de patchs correspondants dans les pilotes qui sont devenus superflus.
Amélioration des performances de la couche de compatibilité: retrait de comparaisons de chaînes de caractères et d’allocations inutiles.
Pilotes spécifiques à Haiku
Amélioration du comportement du pilote USB RNDIS (partage de connexion sur USB de certains téléphones Android) lorsque le câble USB est déconnecté. Le pilote incluait du code pour tenter de restaurer la connexion existante si le même appareil est reconnecté, mais les périphériques RNDIS utilisent des adresses MAC aléatoires qui changent à chaque connexion, donc cela ne pouvait pas fonctionner. De plus, certains transferts USB n’étaient pas correctement annulés pour laisser la pile USB dans un état propre après la déconnexion du périphérique.
USB
Ajout d’une annulation de transferts de données en attente dans le pilote pour les périphériques de stockage USB, ce qui corrige un kernel panic lors de l’utilisation de lecteurs de disquettes USB. Arrêt immédiat des opérations (au lieu de ré-essayer pendant quelques secondes) si le périphérique indique « no media present » (CD ou disquette éjectée de son lecteur par exemple).
Ajout d’une vérification de pointeur NULL et de libération de mémoire manquantes dans la pile USB, ce qui corrige des fuites de mémoires (qui étaient là depuis longtemps) et une assertion qui se déclenchait (introduite plus récemment).
Le pilote de webcam UVC est mis à jour pour utiliser des constantes (identifiants de types de descripteurs…) partagées avec le reste du système au lieu de toutes les redéfinir une deuxième fois. L’affichage des descripteurs dans listusb est également complété pour décoder toutes les informations disponibles. Le pilote n’est toujours pas complètement fonctionnel: l’établissement des transferts au niveau USB fonctionne, mais pour l’instant le pilote ne parvient pas à décoder les données vidéo reçues correctement.
Le pilote HID sait reconnaître les « feature reports », qui permettent de configurer un périphérique. Par exemple, cela peut permettre de configurer un touchpad en mode multi-point (dans lequel le système doit effectuer lui-même le suivi de chaque doigt sur la surface tactile pour convertir cela en mouvements de pointeur de souris) ou en mode émulation de souris (où on ne peut utiliser qu’un doigt à la fois, mais avec un pilote beaucoup plus simple).
Le pilote pour les tablettes Wacom reconnaît la tablette CTH-470.
PS/2
Les ports PS/2 ont disparu de la plupart des machines ces dernières années, mais le protocole reste utilisé pour le clavier des ordinateurs portables, ainsi que pour certains touchpads. Malheureusement, le protocole est seulement émulé au niveau de l’« embedded controller » (le microprocesseur qui se charge de l’interfaçage de divers composants annexes). Le résultat est que l’implémentation du protocole et des registres d’interface peut s’éloigner considérablement des documents officiels.
Amélioration de la détection des contrôleurs PS/2 supportant le protocole « active multiplexing » permettant de connecter à la fois une souris et un touchpad. La procédure de détection officielle peut générer des faux positifs: certains contrôleurs répondent bien à cette commande, mais n’implémentent en fait pas du tout le protocole. Cela provoquait un long délai au démarrage alors que le pilote tente d’énumérer des périphériques de pointage qui n’existent pas. Une vérification supplémentaire après l’activation du mode multiplexé permet de détecter ce cas.
virtio_pci
virtio est un standard matériel pour les machines virtuelles. Plutôt que d’émuler un vrai matériel (carte réseau, carte graphique…), une machine virtuelle peut émuler un matériel qui n’a jamais été fabriqué, mais dont la programmation est beaucoup plus simple. Cela permet également des opérations inimaginables sur du matériel réel, comme la possibilité de changer la taille de la RAM en cours d’exécution pour mieux partager la mémoire de l’hôte entre différentes machines virtuelles.
Le pilote virtio_pci est à la racine du système virtio. Il détecte la « carte PCI » virtio et implémente les primitives de base d’envoi et de réception de messages entre l’hôte et la machine virtualisée (du côté virtualisé, pour le côté hôte, c’est le virtualisateur, par exemple QEMU, qui s’en charge).
Correction de plusieurs problèmes avec les numéros de files virtio qui rendaient les pilotes instables.
ACPI
ACPI est un cadriciel pour la gestion de l’énergie et l’accès au matériel. Le fabricant du matériel fournit (dans la ROM du BIOS) un ensemble de « tables » contenant une description du matériel disponible, ainsi que des méthodes compilées en bytecode pour piloter ce matériel. Le système d’exploitation doit fournir un interpréteur pour ce bytecode, puis réaliser les entrées-sorties vers le matériel demandé lors de l’exécution.
Haiku utilise actuellement ACPICA, une bibliothèque ACPI développée principalement par Intel.
Correction d’un problème d’accès à de la mémoire non cachée. Une modification faite pour les machines ARM a déclenché un problème sur les machines x86.
Sondes de température
Ajout d’un nouveau pilote amd_thermal, ajout de ce dernier ainsi que des pilotes pch_thermal et acpi_thermal dans l’image disque par défaut. Ces pilotes devraient permettre de récupérer la température du processeur sur la plupart des machines. Il reste maintenant à intégrer cela dans les outils en espace utilisateur pour faire un bon usage de ces informations.
Pilotes graphiques
Ajout de deux nouvelles générations de cartes graphiques dans le pilote intel_extreme.
Le pilote VESA est capable de patcher le BIOS de certaines cartes graphiques à la volée pour y injecter des modes graphiques supplémentaires (la spécification VESA permettant à l’OS uniquement de choisir un mode parmi une liste fournie par la carte graphique, liste souvent assez peu fournie). Ce mode est désormais activé par défaut sur les cartes graphiques où il a pu être testé avec succès.
Systèmes de fichiers
FAT
FAT est un système de fichier développé par Microsoft et qui remonte aux premiers jours de MS-DOS. Il est encore utilisé sur certaines clés USB et cartes SD, bien que exFAT tend à le remplacer petit à petit. Il est également utilisé pour les partitions systèmes EFI.
Le pilote de Haiku a été récemment réécrit à partir de celui de FreeBSD. L’amélioration de ce nouveau pilote se poursuit, avec ce mois-ci :
- Les noms de volumes FAT sont convertis en minuscules comme le faisait l’ancien pilote FAT,
- Le cache de blocs implémente maintenant un mécanisme de prefetch pour récupérer plusieurs blocs disque d’un coup, et le pilote FAT utilise cette nouvelle possibilité pour améliorer en particulier le temps de montage,
- Correction de problèmes dans le cache de fichiers si deux applications accèdent au même fichier mais avec des noms différents par la casse (le système de fichier ignorant ces différences).
BFS
BFS est le système de fichier principal de BeOS et de Haiku. Il se distingue des autres systèmes de fichiers par une gestion poussée des attributs étendus, avec en particulier la possibilité de les indexer et d’effectuer des requêtes pour trouver les fichiers correspondants à certains critères.
Clarification de la description des options disponibles lors de l’initialisation d’un volume BFS.
Correction des fonctions d’entrées/sorties asynchrones pour référencer correctement les inodes, ce qui corrige un très ancien rapport de bug. Des corrections similaires ont été faites également dans les pilotes FAT et EXFAT.
Correction des requêtes sur l’attribut « dernière modification », et amélioration de la gestion du type « time » pour éviter les conversions inutiles (ce type d’attribut est historiquement stocké en 32 bits mais migré en 64 bits lorsque c’est possible pour éviter le bug de l’an 2038, aussi le code doit être capable de traiter ces 2 formats de stockage).
packagefs
Le système de fichier packagefs est au centre de la gestion des paquets logiciels dans Haiku. Les paquets ne sont pas extraits sur le disque, mais montés dans un système de fichier spécifique (qui implémente une version tout-en-un de ce qui pourrait être réalisé sous Linux avec squashfs et overlayfs).
Ce système de fichier se trouve donc sur le chemin critique en termes de performances, ce qui fait que même de petites optimisations peuvent déboucher sur de gros gains de performance.
Optimisation de la gestion de la mémoire: utilisation d’un allocateur dédié pour allouer et désallouer très rapidement de la mémoire de travail avec une durée de vie courte.
Ajout d’une vérification manquante sur la présence du dossier parent, qui pouvait déclencher un kernel panic.
NFS4
Le pilote NFS4 permet de monter des partages réseau NFS. Cependant, le pilote ne fonctionne pas toujours, et certains utilisateurs doivent se rabattre sur le pilote NFS v2 (ancienne version du protocole de moins en moins utilisée), ou encore sur des systèmes de fichiers FUSE comme SMB ou sshfs.
Le pilote NFS4 peut maintenant être compilé avec userlandfs (équivalent de FUSE pour Haiku) pour s’exécuter en espace utilisateur. Cela facilitera le déboguage.
ramfs et ram_disk
ram_disk est un périphérique de stockage qui stocke les données en RAM, il a une taille fixe et doit être formaté avec un système de fichiers avant de pouvoir être utilisé.
ramfs est un système de fichier stockant les données directement en RAM sans passer par un périphérique de stockage de type bloc. Sa taille est dynamique en fonction des fichiers qui sont stockés dedans.
Ces deux pilotes ont reçu divers nettoyages et corrections, suite à des problèmes mis en évidence par des assertions ajoutées précédemment dans le code.
Dans le ramfs, nettoyage de code dupliqué, réduction de la contention sur les verrous, amélioration de la fonction readdir pour retourner plusieurs entrées d’un coup au lieu de les égréner une par une.
Ajout de la gestion des fichiers « spéciaux » (FIFOs nommés, sockets UNIX) dans ramfs.
Autres
Refonte de l’algorithme de « scoring » des requêtes sur les systèmes de fichiers. Cet algorithme permet d’estimer quels sont les termes de la requête les moins coûteux à évaluer, afin de réduire rapidement le nombre de fichiers répondant aux critères, et d’effectuer les opérations complexes seulement sur un petit nombre de fichiers restants. Les requêtes s’exécutent ainsi encore plus rapidement (waddlesplash).
Réécriture du code pour identifier les partitions dans mount_server. Ce code permet de re-monter les mêmes partitions après un redémarrage de la machine, mais l’ancien algorithme pouvait trouver de faux positifs et monter des partitions supplémentaires (OscarL et waddlesplash).
Correction d’une option de debug pour intercepter les accès aux adresses non initialisées (0xcccccccc) ou déjà libérées (0xdeadbeef). Cela permet de détecter certains accès à des pointeurs invalides. Cette option ne fonctionnait correctement que sur les systèmes 32 bit, maintenant, l’adresse correspondante pour les machines 64 bit est également protégée.
libroot
La libroot est la librairie C de base de Haiku. Elle regroupe les fonctions parfois implémentées dans les libc, libm, libpthread, librt et libdl pour d’autres systèmes. Haiku choisit une approche tout-en-un, car il est excessivement rare qu’une application n’ait pas besoin de toutes ces bibliothèques.
Du fait de la grande diversité des services rendus par cette bibliothèque, il est difficile de présenter les changements de façon cohérente et organisée.
Correction de quelques cas particuliers dans le traitement des tableaux de descripteurs de fichiers pour select() et déplacement d’une partie des définitions de sys/select.h vers des en-têtes privés non exposés aux applications (waddlesplash).
Ajout d’une fonction manquante dans les « stubs » de la libroot, qui sont utilisés lors de la compilation de Haiku en mode « bootstrap » (sans aucune dépendance précompilée externe). Les stubs sont normalement générés à l’aide d’un script, mais celui-ci n’avait pas pris en compte une fonction nécessaire seulement sur les architectures x86.
Poursuite du travail d’unification des fonctions de manipulation des temps d’attentes pour toutes les fonctions de la libroot qui peuvent déclencher un timeout. Correction d’un cas où la fonction pthread_testcancel retournait NULL au lieu de la valeur attendue PTHREAD_CANCELED.
Optimisation de la fonction strcmp, remplacement d’autres fonctions avec de meilleures implémentations provenant de la bibliothèque C musl.
Compatibilité POSIX-2024
La spécification POSIX Issue 8 a été publiée et comporte de nombreux changements. Après la version 7, la façon de travailler est devenue plus ouverte, avec un outil de suivi de bugs permettant de proposer des améliorations. Cela conduit à la standardisation de nombreuses extensions qui sont communes entre les systèmes GNU et BSD, rendant plus facile d’écrire du code portable entre tous les systèmes compatibles POSIX.
- Ajout de fonctions qui ouvrent des descripteurs de fichiers avec le drapeau O_CLOEXEC activé par défaut (
dup2, pipe3)
- Ajout de
reallocarray (un mélange de calloc et realloc)
- Ajout de
memmem (recherche d’une suite d’octets dans une zone de mémoire)
- Ajout de
mkostemp
- Ajout de
posix_devctl et modifications de l’implémentation de ioctl
- Ajout de
pthread_getcpuclockid pour mesurer le temps CPU consommé par un thread
- Ajout de la constante d’erreur
ESOCKTNOSUPPORT bien qu’elle ne soit jamais utilisée (cela facilite le portage d’applications qui attendent l’existence de ce code d’erreur)
- Correction d’une boucle infinie dans
pipe2
- Suppression des fonctions
*randr48_r des en-têtes publics. Il s’agit d’une extension disponible uniquement dans la glibc, et qui ne devrait donc pas être disponible dans la libroot. Cependant, l’implémentation est conservée pour assurer la compatibilité d’ABI avec les applications existantes.
ioctl et posix_devctl
La fonction ioctl existe depuis le début de UNIX et permet de réaliser des opérations spéciales sur les descripteurs de fichiers (tout ce qui n’est pas une simple lecture ou écriture). En particulier, elle est beaucoup utilisée pour les pilotes de périphériques qui exposent une interface sous forme de fichiers dans /dev.
L’existence de cette fonction était demandée dans la spécification POSIX, mais son fonctionnement n’était pas documenté à l’exception de quelques cas particuliers. La documentation spécifie une fonction avec un nombre d’arguments variable : un numéro de descripteur de fichier, un identifiant de l’opération à effectuer, puis des paramètres qui dépendent de l’opération. On trouve des opérations avec aucun, un, ou deux paramètres.
Dans UNIX et la plupart de ses dérivés, la liste des opérations possibles est définie à l’avance, et le format des numéros identifiants permet de déterminer de façon prédictible quel est le nombre de paramètres attendus. Ce n’est pas le cas dans Haiku : les pilotes de périphériques ont le choix d’assigner n’importe quelle valeur à n’importe quelle opération, et la même valeur numérique peut donc avoir une signification différente selon le type de fichier.
L’opération ioctl est donc en réalité implémentée avec toujours 4 arguments pour Haiku : en plus des deux déjà mentionnés, il faut ajouter un pointeur vers une zone de mémoire, et un entier indiquant la taille de cette zone. Des acrobaties à base de macros permettent de remplir ces deux paramètres avec des valeurs par défaut lorsqu’ils ne sont pas nécessaires (au moins pour les programmes écrits en C ; en C++, ces deux paramètres sont simplement déclarés avec une valeur par défaut).
Heureusement, ces problèmes avec ioctl vont être résolus, puisque POSIX a introduit une nouvelle fonction en remplacement : posix_devctl. Celle-ci fonctionne comme l’implémentation de ioctl dans Haiku, mais les arguments doivent toujours être spécifiés explicitement. Cela va donc permettre de disposer d’une interface réellement portable pour ces opérations.
Kernel
Correction de la taille du tampon mémoire par défaut de la classe KPath qui permet au noyau de manipuler des chemins dans le système de fichiers (waddlesplash).
VFS
Le VFS (virtual filesystem) est l’interface entre les appels systèmes d’accès aux fichiers (open, read, write…) et les systèmes de fichiers proprement dit. En plus de ce travail d’interfaçage (par exemple : convertir un chemin de fichier absolu en chemin relatif à un point de montage), cette couche regroupe un ensemble de fonctionnalités qui n’ont pas besoin d’être réimplémentées par chaque système de fichier: vérification des permissions, mémoire cache pour limiter les accès au disque.
Si les systèmes de fichiers identifient chaque objet par un inode (en général lié à la position de l’objet sur le disque ou dans la partition de stockage), le VFS travaille lui avec des vnode qui existent uniquement en RAM et sont alloués dynamiquement pour les fichiers en cours d’utilisation.
D’autre part, les systèmes de fichiers peuvent se reposer sur un cache de blocs. Ce dernier se trouve plutôt à l’interface entre un système de fichier et le support de stockage correspondant, puisqu’il fonctionne au niveau des blocs de données stockées sur disque. Mais son intégration avec le VFS est nécessaire pour savoir quels sont les fichiers en cours d’utilisation et les opérations prévisibles sur chacun (par exemple, il est utile de pré-charger la suite d’un fichier lorsque un programme demande à en lire le début, car il est probable que ces informations vont bientôt être nécessaires).
Le VFS est donc un élément central en particulier pour obtenir de bonnes performances sur les accès aux fichiers, en minimisant les accès aux vrais systèmes de fichiers qui doivent maintenir beaucoup d’informations à jour sur les disques. Tout ce qui peut être traité en utilisant uniquement la RAM grâce à la mise en cache est beaucoup plus rapide.
Investigation et amélioration des performances de la commande git status qui prenait beaucoup plus de temps à s’exécuter que sur d’autres systèmes (waddlesplash):
- Meilleure gestion des vnodes inutilisés à l’aide d’une liste chaînée 'inline' protégée par un spinlock, à la place d’un mutex peu performant dans ce code très fréquemment appelé.
- Modification de la structure
io_context pour utiliser un verrou en lecture-écriture (permettant plusieurs accès concurrents en lecture, mais un seul en modification).
- Ajout d’un chemin rapide dans le cas le plus simple de la recherche de vnode.
Avec ces changements, les performances sont améliorées au moins lorsque les données nécessaires sont déjà disponibles dans le cache disque.
Nettoyage et corrections dans les fonctions d’entrées-sorties vectorisées et asynchrones do_iterative_fd_io et do_fd_io utilisées par les systèmes de fichiers: meilleure gestion des références et prise en compte de certains cas particuliers. Cela permet de simplifier un peu le code de pré-remplissage du cache de blocs (waddlesplash).
La prise en compte des drapeaux O_RDONLY|O_TRUNC lors de l’ouverture d’un fichier est maintenant faite directement dans le VFS, il n’est plus nécessaire de transmettre la requête au système de fichier. Cette combinaison de drapeaux est un comportement indéfini dans POSIX, et supprime le contenu du fichier dans Linux. Dans Haiku, elle remonte une erreur.
Correction du comportement de l’ouverture d’un symlink invalide (ne pointant pas sur un fichier) avec le flag O_CREAT.
Le parser de requêtes pouvait essayer de lire des données invalides (la taille de clé d’un index inexistant) dans certains cas particuliers.
Nettoyage de logs dans tous les systèmes de fichiers qui affichaient un message lors de chaque tentative d’identification. On avait donc un message de chaque système de fichier pour chaque partition. Maintenant, le cas le plus courant (le système de fichier ne reconnaît pas du tout la partition) ne déclenche plus de logs.
Correction d’une erreur dans userlandfs sur la fonction file_cache_read pour les tentatives d’accès après la fin d’un fichier (cas particulier nécessaire pour implémenter correctement mmap).
Correction d’une mauvaise gestion du errno dans le cache de blocs, qui pouvait aboutir à un kernel panic.
Diverses améliorations, nettoyages et corrections de fuites mémoire: dans la gestion des fichiers montés comme image disques, dans les entrées-sorties asynchrones, dans l’enregistreur d’évènements scheduling recorder.
Console et affichage
Unification du code d’affichage du splash screen (par le bootloader) et des icônes de la séquence de démarrage (par le kernel) pour éviter qu’ils prennent des décisions différentes sur le positionnement (par exemple si l’un est compilé pour afficher le logo de Haiku, et l’autre en version « dégriffée » sans ce logo qui est une marque déposée) (waddlesplash).
Initialisation de la console framebuffer beaucoup plus tôt dans le démarrage du noyau, ce qui permet d’afficher un message à l’écran en cas de kernel panic y compris dans les premières étapes du démarrage (par exemple, l’initialisation de la mémoire virtuelle). Auparavant, ces informations étaient disponibles uniquement dans le syslog (inaccessible si le système ne démarre pas) ou via un port série (en voie de disparition sur les machines modernes) (waddlesplash).
Réseau
Remontée des données annexes (ancillary data) en une seule fois lorsque c’est possible. Ces données sont utilisées en particulier dans les sockets de domaine AF_UNIX pour permettre d’échanger des descripteurs de fichiers entre processus. Ce regroupement de données n’est pas exigé par la spécification POSIX, mais c’est le comportement attendu par le code de communication interprocessus de Firefox et de Chromium (ils utilisent tous les deux le même code) (waddlesplash).
Gestion de la mémoire
Comme indiqué plus haut dans la dépêche, l’apparition du navigateur Iceweasel a mis en évidence de nombreux problèmes autour de la gestion de la mémoire. Cela a donc été l’objet d’un gros travail de stabilisation et d’amélioration.
- Le cache d’objets du noyau pouvait parfois ignorer le paramètre indiquant la réserve minimum d’objets devant toujours être disponibles (waddlesplash)
- Amélioration de l’implémentation de la famille de fonctions autour de
mprotect, qui permettent une gestion fine et bas niveau de la mémoire. En particulier, plusieurs problèmes se posaient lors de l’utilisation de ces fonctions lors d’un appel à fork, les deux processus se retrouvant dans un état incohérent,
- Suppression de logs présents dans les méthodes de défaut de page, qui sont peu appelées pour les applications classiques, mais exploitées volontairement par d’autres applications (machines virtuelles Java ou Javascript par exemple). Les logs étaient donc superflus dans ce cas (waddlesplash),
- Optimisation de l’écriture par lot de plusieurs pages de mémoire vers le swap,
- Meilleure gestion des permissions d’accès page par page,
- Correction de plusieurs problèmes conduisant à un blocage ou fort ralentissement du système quand il n’y a plus assez de mémoire libre,
- Amélioration de la stratégie d’allocation de la table des descripteurs de fichiers,
- Regroupement de code dupliqué pour chaque plateforme qui était en fait générique.
Ce travail se poursuit avec un remplacement de l’allocateur mémoire actuel, qui est basé sur hoard2. Cette implémentation est assez ancienne et montre aujourd’hui ses limites. Des essais sont en cours avec l’implémentation de malloc d’OpenBSD, ainsi qu’avec mimalloc de Microsoft, pour déterminer lequel des deux sera utilisé. D’autres allocateurs ont été rejetés, car ils ne répondent pas au besoin de Haiku, en particulier la possibilité de fonctionner efficacement sur un système 32 bits ou l’espace d’adressage est une ressource limitée.
Autres
Sécurisation des permissions sur les zones mémoire partagées: une application ne peut pas ajouter des permissions en écriture aux zones mémoire d’une autre application. Une application qui n’est pas lancée par l’utilisateur root ne peut pas inspecter la mémoire d’une application lancée par l’utilisateur root. Ajout toutefois de cas particuliers pour permettre au Debugger de faire son travail (il a besoin d’accéder à la mémoire d’autres applications).
Ajout et amélioration de commandes dans le debugger noyau pour investiguer l’état de l’ordonnanceur d’entrées-sorties, qui se charge de programmer les accès disque dans un ordre le plus efficace possible (waddlesplash).
La fonction vfork n’appelle plus les fonctions pre-fork. Haiku n’implémente pas complètement vfork, mais peut se permettre des optimisations sur le travail qu’un duo fork + exec classique demanderait normalement.
La configuration de la randomization de l’espace mémoire (ASLR) est maintenant faite par la libroot et pas par le noyau. Ainsi une application peut utiliser une version différente de la libroot pour avoir une politique de randomization différente.
Optimisation de l’accès par un thread à sa propre structure Thread
Chargeur de démarrage
L’écran de démarrage s’affiche correctement sur les systèmes EFI utilisant un mode écran avec une profondeur de couleur 16 bits (korli).
Affichage de la taille des partitions démarrables dans le menu de démarrage, pour faciliter leur identification (waddlesplash).
Activation des warnings du compilateur sur les chaînes printf invalides.
Augmentation de la zone de mémoire utilisée pour la décompression de l’archive de démarrage lors du boot sur le réseau, l’archive était devenue trop grosse suite à l’ajout de nouveaux pilotes.
Refactorisation du code de gestion de la mémoire entre le bootloader et le runtime_loader, ajout de tests pour cette implémentation, et optimisation de l’utilisation mémoire du bootloader.
Amélioration du comportement si le device tree définit un port série sans spécifier de baudrate: le bootloader suppose que le baudrate est déjà configuré, et utilise le port sans essayer de le réinitialiser.
Outils de compilation
La compilation de Haiku est un processus relativement complexe: il faut utiliser deux compilateurs pour Haiku lui-même (un gcc récent plus une version plus ancienne pour assurer la compatibilité avec BeOS) ainsi que un compilateur pour le systême hôte de la compilation (qui peut être Linux, BSD, Mac OS ou Windows) pour générer des outils nécessaires à la compilation elle-même. L’outil retenu est Jam, une alternative à Make avec une meilleure gestion des règles génériques réutilisables.
- Ajout de vérification pour éviter d’avoir un build partiellement configuré, avec des
ConfigVars définies mais vides.
- Retrait d’un warning incorrect dans l’outil de build
jam si on spécifie à la fois un profil et une cible de compilation sur la ligne de commande.
- Reconnaissance des processeurs hôtes ARM et RISC-V pour la compilation croisée, correction d’autres problèmes avec les architectures non-x86.
- Ajout de dépendances manquantes dans les règles de compilation de packagefs.
- Suppression de fichiers de licence fournis avec Haiku mais concernant du code qui avait été supprimé de Haiku auparavant.
- Amélioration de la remontée d’erreur du script configure si un interpréteur Python n’a pas été trouvé.
- Correction de messages d’avertissement de
awk pour l’utilisation de fonctions qui n’existent plus dans le traitement des fichiers d’identifiants matériels USB et PCI.
Documentation
Documentation interne
Ajout de documentation sur les détails d’implémentation de ioctl et posix_devctl et les spécificités de Haiku pour la première (PulkoMandy).
Correction de fautes de frappe dans l’introduction au launch_daemon.
Remplacement de toutes les références à "OpenBeOS" par "Haiku".
Documentation d’API
Ajout de documentation pour les méthodes GetFontAndColor et SetFontAndColor de BTextView.
Ajout de documentation pour les classes BShelf et BGameSound.
Réorganisation de la liste des caractères de contrôles dans la documentation du clavier, ajout d’entrées manquantes dans cette liste et ajoute de commentaires indiquant à quelles combinaisons de touches ces caractères sont normalement associés.
Traductions de Haiku
La traduction du système dans différentes langues est un facteur important d’inclusivité et d’accessibilité (même si la communication avec l’équipe de développeurs pour le support n’est pas toujours simple).
Haiku est disponible dans 30 langues, la trentième étant le coréen, pour lequel il y a un nouveau responsable des traductions (le précédent avait cessé toute activité et laissé la traduction inachevée).
Haiku recherche des volontaires pour s’occuper des traductions en biélorusse, croate, bulgare, hindi, punjabi et slovène, pour lesquelles les précédents responsables de relectures n’ont plus le temps d’assurer le rôle. Ainsi bien sûr que de l’aide pour la traduction du système, du manuel d’utilisation, et des applications tierces, que ce soit pour ajouter de nouvelles langues ou pour renforcer les équipes s’occupant de langues existantes. Le point d’entrée est le portail d’internationalisation de Haiku.
La traduction du système Haiku s’effectue avec Pootle. L’outil n’est plus développé et des investigations sont en cours pour le remplacer par Weblate. La traduction du manuel d’utilisation s’effectue avec [un outil spécifiquement développé pour cela](https://github.com/haiku/userguide-translator. La traduction des applications s’effectue également avec un outil personnalisé nommé Polyglot.













































































 Laisse-moi goûter à cette version !
Laisse-moi goûter à cette version !




















{kind=link}